 블로그 > 인생의 자유는 모두의 권리입니다.... 블로그 > 인생의 자유는 모두의 권리입니다.... http://blog.naver.com/hdchong/100006713656 http://blog.naver.com/hdchong/100006713656 | |
로드밸런싱 (load balancing) 만약 www.naver.com으로 접속한다고 치고 네이버에 웹서버가 두대가 있다면 금강제화 로드밸런싱 구축 사례
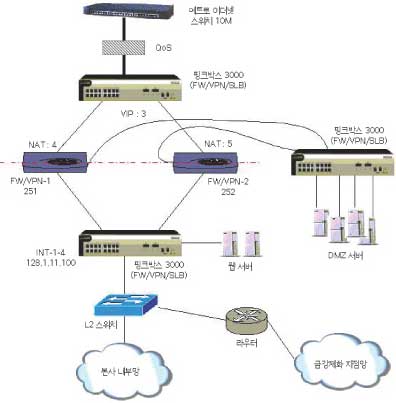
지난 1954년부터 ‘최고가 아니면 판매하지 않는다’를 모토로 국내 제화산업을 이끌어온 금강제화 (대표 신용호 www.kumkang.com)는 지난해 늘어나는 내부 트래픽을 제어하기 위해 파이오링크 ‘핑크박스 3000’을 구매했다.
핑크박스가 막 출시된 시점이라 안정성에 대한 검증 등에 대해 의문이 많았지만 최신제품으로 최고의 네트워크를 구축하자는 신념으로 성공적으로 구축, 안전하게 쓰고 있다. 금강제화의 핑크박스 활용 사례를 들여다본다.
지난해 금강제화는 파이어월과 VPN 통합장비를 구입, VPN을 도입하면서 부하분산에 대한 필요성이 두드러졌다. 이에 따라 늘어나는 내부 트래픽 증가를 효율적으로 처리해주기 위해 파이어월과 VPN 통합장비를 추가로 구매할 계획을 세웠다. 또 파이어월/VPN 통합장비 2대 사용으로 이중화 구성을 위한 로드밸런싱 장비가 필요했고 내부 서버 트래픽 부하분산을 위해서 L4 스위치 도입을 고려하게 됐다.
외산장비를 포함한 여러 장비업체들의 제안서를 검토한 결과 금강제화는 신속한 지원과 커스트마이징이 용이한 국산장비를 도입하는 것이 낫겠다는 판단 아래 파이오링크의 L4스위치를 도입하기로 결정했다.
금강제화가 로드밸런싱을 위해 파이오링크의 L4 스위치 도입을 결정했을 당시는 핑크박스 3000이 출시되기 전이었다. 핑크박스 1508을 도입하기로 결정하고 프로젝트를 진행하던 중 파이오링크에서 핑크박스 3000을 출시했고 금강제화는 내부회의를 거쳐 3000을 도입하기로 변경했다. 물론 이 선택에 대해 반대하는 의견도 만만찮았다.
신규 출시되는 장비에 대한 안정성, 신뢰성 등을 의심, 3000보다 검증된 1508로 가는 게 더 낫지 않겠냐는 의견이 지속적으로 제기됐지만 기왕이면 앞선 성능의 제품으로 더 나은 네트워크를 구성해보자는 전산실의 의견을 수렴하게 됐다.
금강제화 기획조정본부 전산실 김경준 과장은 “1508의 경우 파이어월 로드밸런싱(FLB)과 서버 로드밸런싱(SLB)를 별도로 수행해야했지만 3000은 FLB와 SLB를 한 장비에서 통합 구현할 수 있다” 며 “이런 통합기능으로 인해 5대 이상 구입해야할 L4 스위치 장비를 3대로 줄여 네트워크 구성이 간편해졌다”고 만족해했다.
또 그는 “프로젝트 초기에는 처음 설치해보는 제품이라 여러 가지 문제도 발생했지만 파이오링크에서 최대한 지원해줬고 장기적으로도 최신장비를 구입해야 몇 년동안 업그레이드에 대한 걱정 없이 운영할 수 있을 것 같아 초기의 어려움을 감수했다”고 덧붙였다. 현재 금강제화는 파이어월/VPN용으로 한 대와 파이어월/VPN/SLB용으로 2대, 3세 대의 핑크박스 3000, 그리고 지점망에 핑크박스 1508을 운영하고 있다.
지난해 2월 L4 스위치 장비 도입 계획을 세운 후 자체 개발기간 6~7개월을 거쳐 실제로는 9월부터 설치에 들어갔고 약 한달간의 안정화기간을 거쳐 지난해 10월말부터 본격적으로 가동하고 있는 상태다. 현재까지는 아무런 장애 없이 늘어난 트래픽을 효과적으로 제어하며 만족스럽게 쓰고 있다.
김 과장은 “핑크박스 3000이 내부 트래픽을 각 서버의 상황에 따라, 트래픽의 종류에 따라 로드밸런싱이 가능해 약 50% 이상 속도가 향상됐다”며 “빨라진 속도로 인해 직원들의 만족도도 높아져 업무능률이 향상됐다”고 언급했다.
금강제화에 설치된 다계층 스위치 ‘핑크박스 3000’은 로드밸런싱 기능을 통해 서버, 캐시 서버, 네트워크 보안 장비(파이어월, VPN), IDS 등의 높은 가용성은 물론이고, 원활한 처리 속도를 제공하는 제품이다. 이 제품은 패킷을 고속 처리하고 동시에 100만 개 이상의 세션을 처리할 수 있어 사용자가 많은 대규모 환경에 적합하다.
일반적인 다계층 스위치의 용도가 웹 서버, 캐싱 서버, 파이어월 등 각종 서버의 로드밸런싱, 장애복구 기능을 돕는 데 있는 만큼, 핑크박스 3000도 이런 기능을 기본으로 제공한다. 여러 종류의 로드밸런싱 기능을 동시에 지원할 수 있도록 설계돼 핑크박스 3000 1대로 다양한 로드밸런싱 용도로 사용할 수 있다. 금강제화가 특히 만족하는 부분도 바로 이러한 여러 종류의 로드밸런싱 기능을 동시에 지원할 수 있다는 점이다.
금강제화는 VPN 로드밸런싱, 서버 로드밸런싱, 파이어월 로드밸런싱 등 다양한 로드밸런싱 기능을 한 장비에서 동시에 구현함으로 관리 편이성과 네트워크 구성 용이성 등의 이점을 톡톡히 누리고 있다.
김경준 과장은 “VPN 구축과 함께 문제로 대두된 VPN 트래픽을 효과적으로 처리해줄 방법을 찾고 있었는데 핑크박스의 VPN 로드밸런싱의 경우, 지점 VPN 장비에서 센터 장비로의 접속 뿐 아니라, 센터에서 지점으로의 접속도 허용함으로써 VPN 네트워크를 100% 활용할 수 있는 환경을 제공한다”며 “따라서 이런 다양한 로드밸런싱을 통해 인터넷 서비스의 성능을 극대화하고 트래픽 관리를 고차원적으로 수행할 수 있다”고 언급했다.
또 핑크박스 3000은 중요한 대역폭 관리를 위한 QoS (Quality of Service)기능은 트래픽 유형별 대역폭 보장, 사용자의 우선 순위 설정에 따른 대역폭 제한을 통해 제공한다. IP 어드레스, 포트 번호 수준의 트래픽 구분 외에도 URL, 쿠키, HTTP 헤더 등 7계층 정보에 의한 트래픽 구분을 통해 정교한 대역폭 관리 기능을 제공하는 것도 강점이다. 이런 QoS 기능으로 인해 주요 트래픽과 단순 인터넷 접속 트래픽 등을 분류, 업무에 중요한 트래픽에 우선 순위를 할당할 수 있어 업무효율성도 증가했다.
한편 금강제화는 강남지점에 네트워크 로드밸런싱 장비인 ‘핑크박스 1508’을 설치, 운영중이다. 이 장비는 전용선을 포함한 다수(7회선)의 초고속인터넷 회선을 결합해 하나의 회선처럼 동작하게 함으로써 대용량(최대 100Mbps)의 안정적인 인터넷 접속을 제공해 최고 100Mbps의 대역폭 확보가 적은 비용으로 가능하다. 다중의 회선을 사용하기 때문에 안정성도 매우 뛰어나다.
김 과장은 “지난 1년동안 강남지점에 핑크박스 1508을 설치 후 128Kbps의 전용선과 ADSL 3회선을 동시에 사용하게 될 경우와 E2 1회선을 사용하는 경우를 비교해봤더니 전자의 경우가 속도에서도 월등할 뿐만 아니라 최소 천 만원 이상의 비용절감이 가능한 것으로 나타났다”며 “향후에는 보안 등의 문제로 인해 E1, T3 등으로 회선을 증설, 양재동 본사쪽으로 트래픽을 통합해야겠지만 현재로서는 강남지점의 운영상태가 좋아 강남지점외의 타 지점, 영업소 등을 같은 방법으로 운영할 것으로 고려하고 있다”고 언급했다.
향후 금강제화는 전국 매장 280곳과 계열사 등을 통합하면 약 600노드 이상이 될 것으로 예상, 이를 통합하게 되면 발생할 대량 트래픽에도 로드밸런싱 장비로 적절히 제어할 수 있을 것으로 기대하고 있다. 또 침입탐지, 바이러스월 등 보안장비를 추가로 도입, 안전한 네트워크 구성을 위해 만전을 기할 방침이다.
[생각]=============================================================== 저희도 L4장비를 검토중에 있는데..제품에 대한 기술적인 자료등이 오픈이 안되어 비교하기가 수월하지 않더군요..L4장비는 서버,VPN,방화벽등의 장비 사이에 설치하며 트래픽 로드밸런싱 기능으로 장비를 효율적으로 사용하고 장애시에 트래픽을 우회함으로써 장애예방이 주 목적이지요
인터뷰에서는 50% 속도 향상이라고 표현했는데 방화벽 이중화로 인한 향상이며 L4장비는 보조적인 지원이라고 봐야 하겠지요 ^^
대기업에서도 수익율로 네트워크 장비개발에 미온적인데 국내벤쳐에서 개발하여 동남아 시장에 판로개척을 하는것을 보면 흐믓합니다
지난 1954년부터 ‘최고가 아니면 판매하지 않는다’를 모토로 국내 제화산업을 이끌어온 금강제화(대표 신용호 www.kumkang.com)는 지난해 늘어나는 내부 트래픽을 제어하기 위해 파이오링크 ‘핑크박스 3000’을 구매했다. Windows2000Pro를 사용해서 로드밸런싱게이트웨이를 구성하신다는것이신지(이건 윗분말씀처럼 다른OS와 추가로 더 깔아야합니다.) 아니면 Windows2000들을 로드밸런싱을 하신다는것이신지... 로드밸런싱 (리눅스 편) 심마로, 리눅스원(주) 연구원 목차 1. 리눅스 로드 밸런싱 (1) 로드밸런싱이란? (2) 리눅스 로드 밸런싱의 목적 (3) 리눅스 로드 밸런싱의 구성 2. 리눅스 로드 밸런싱 솔루션 (1) 리눅스 가상 서버 LVS(Linux Virtual Server) (2) 레드햇의 피라냐(RedHat Piranha) (3) 기타 상용 솔루션 3. 리눅스 고가용성 솔루션 (1) 리눅스 고가용성 솔루션의 개요 (2) Kimberlite/Convolo Cluster (3) OPS(Oracle Parallel Server) 4. 프로세스 마이그레이션 (1) 프로세스 마이그레이션 개요 (2) Mosix (3) Scyld 5. 맺음말
1. 리눅스 로드 밸런싱
(1) 로드밸런싱이란? 로드밸런싱을 간단히 정의하자면, 여러 컴퓨터에 작업을 균등하게 분산시킴으로써 한 대의 컴퓨터를 사용하는 것에 비해 짧은 시간에 사용자가 원하는 작업을 수행하고자 하는 것이다. 수십 대의 컴퓨터를 사용한다고 하더라도 주로 한 대의 컴퓨터에서 작업이 이루어진다면 원하는 성능 향상을 얻을 수 없을 것이기 때문에, 작업을 "균등"하게 분산시키는 것이 중요하다. 로드밸런싱을 위해서 전용 하드웨어를 사용할 수도 있고, 일반적인 컴퓨터와 일반적인 운영체제를 사용할 수도 있으며, 또한 처리 수준 측면에서는 응용 프로그램 레벨과 IP 레벨에서 로드 밸런싱을 처리할 수 있다. 이 글에서는 주로 일반적인 운영체제를 사용하는 경우, 그리고 IP 레벨에서 로드밸런싱을 처리하는 경우를 다룰 것이다.
(2) 리눅스 로드밸런싱의 목적 리눅스 로드밸런싱의 목적은 리눅스 서버를 클러스터로 연결하여 전체적으로 저렴한 가격에 높은 성능을 제공하는 것이다. SMP 시스템이라고 부르는 공유 메모리 방식의 서버 시스템의 경우, CPU 갯수가 2개, 4개, 8개 등으로 증가함에 따라서 가격이 기하급수적으로 증가하기 때문에, 확장성이 좋지 못하다. 따라서 수십 ~ 수백 대의 서버가 요구되는 경우 클러스터 설정을 사용하게 된다. 또한 수십 ~ 수백 대의 서버에서 사용하는 운영체제로서 리눅스를 사용하는 것이 안정적이고 성능이 우수하며, 가격도 저렴하기 때문에 효과적이다. 클러스터 설정을 위해 사용되는 하드웨어는 공간 비용을 절약하기 위해 1.75"(약 4.5cm) 높이의 1U 랙 마운트 케이스를 사용하는 추세이다. 물론, 응용에 따라서는 수십 개의 CPU가 공유 메모리 방식으로 연결된 SMP 시스템을 요구하는 경우도 있다. 예를 들어 Sun사의 Starfire 구조(Sun Enterprise 10000)의 경우 64 CPU까지 지원한다. 하지만 응용 프로그램의 수정을 통해서 로드밸런싱 클러스터에서 실행시키는 것이 가능하다면, SMP 시스템에 비해 높은 가격대 성능비를 얻을 수 있다. 그리고, 서버의 수가 증가함에 따라 에러가 발생할 확률이 증가하므로 이를 해결하기 위해 추가적으로 고가용성(High Availability)을 제공한다. 고가용성은 전체 시스템의 각 부분에서 모두 필요한데, 이에 대해서는 3절에서 설명한다. (3) 리눅스 로드밸런싱의 구성 이 글에서는 리눅스 로드 밸런싱을 위해 다음과 같은 일반적인 구성을 가정하였다. <논리적인 구성>
<물리적인 구성>
<전체적인 시스템 구성>
로드 밸런서 2대는 Active-Passive 설정(두 대의 서버가 동시에 사용자의 요청을 처리하는 것이 아니라, Active 상태인 하나의 서버만 사용자의 요청을 처리하며, Passive 상태인 서버는 Acitve 상태인 서버가 제대로 동작하는지 감시하고 있다가, 오동작을 하는 경우 사용자의 요청을 넘겨 받아 작업을 처리한다)이며, 한 대로 설정하는 경우 발생할 수 있는 로드 밸런서의 에러로 인한 전체 서비스의 중단을 막기 위해 2대로 설정한다. 로드 밸런서를 위한 하드웨어는 CPU 성능이나 메모리 용량이 크게 요구되지 않지만, 하드웨어의 안정성이 중요하다. 서버 노드는 로드 밸런서에서 작업을 분배시켜 준 것을 받아서 실제로 작업을 수행한다. 여기서는 8대의 서버 노드를 가정하였다. 그렇지만, 실제로는 설정에 따라서 수십 ~ 수백 대의 서버 노드를 연결할 수 있다. 1U 랙마운트 케이스에 듀얼 CPU 설정을 많이 사용한다. 데이터베이스 서버 노드 두 대 역시 Active-Passive 설정이며, 이 부분에 대해서는 3절, "리눅스 고가용성 솔루션"에서 자세히 설명한다. 공유 SCSI 외장형 스토리지는 데이터베이스 서버 노드 두 대에 외장 SCSI 케이블로 연결되며, 스토리지 내부는 RAID로 구성되어 서비스의 중단을 방지한다. 100Mbps 이더넷 스위치는 이 시스템의 로드 밸런서 및 서버 노드들 사이의 연결을 위해 사용된다. 앞의 설정에서는 외부 인터넷과 서버의 연결, 서버와 데이터베이스 연결을 위해 별도의 이더넷 스위치를 사용한다고 가정했다. 그러나, 이더넷 스위치의 포트가 넉넉하다면, 로드밸런서와 서버 노드 사이의 연결과, 서버 노드와 데이터베이스 서버 노드 사이의 연결을 모두 하나의 이더넷 스위치로 연결할 수 있다. 이와 같은 시스템 설정에서 오동작으로 인해 전체 시스템의 서비스 중단을 일으킬 수 있는 부분은 개별 서버가 아니라 서버간의 연결을 담당하는 네트워크 스위치이다. 따라서 품질이 우수한 이더넷 스위치를 사용할 필요가 있다. (로드밸런싱 솔루션 중에서 로드 밸런서 2대에 의한 failover만으로는 로드 밸런서의 에러에 의한 서비스 중단을 방지하기에 불충분하다고 주장하며, 따라서 살아 있는 다른 서버로 로드 밸런서의 이전을 제공하는 솔루션들도 있다. 하지만, 필자의 생각으로는 이와 같은 시스템 설정에서 과부하 상황에서 문제가 발생할 수 있는 부분은 이더넷 스위치를 비롯한 네트워크 인터커넥션 부분이며, 이에 대한 충분한 품질 검사가 필요하다고 생각한다. 또한, 계속되는 과부하 상황에서 로드밸런서가 다른 서버로 이전되기 위한 네트워크 부하의 증가와, 이전 후의 충분하지 못한 서버 용량 때문에 정상적인 서비스 지속은 불가능할 것으로 생각한다) 박스 : <IBM의 올림픽 사이트 관련>1998년 나가노 동계 올림픽 공식 홈페이지는 당시에 다음과 같은 기록을 세웠다. (기네스북 인증) * 사상 최고의 가장 인기있는 인터넷 이벤트 - 공식적으로 감사된 수치는 올림픽 게임 16일동안 6억 3천4백만 요청. * 1분동안 가장 많은 히트를 기록한 인터넷 사이트 - 공식적으로 감사된 수치는 여자 자유종목 피겨스케이팅 경기중의 1분동안 110,414히트를 기록. 이 사이트의 구축을 위해 TCP 수준에서의 라우팅에 기반한 로드 밸런싱 기법을 사용하였다. 클러스터의 한 노드는 TCP 라우터라고 불리는데, 클라이언트의 요구를 라운드 로빈 또는 다른 방법을 사용해서 클러스터 내의 웹 서버 노드로 전송한다. 라우터의 도메인 이름과 IP 주소는 외부에 공개되어 있고, 클러스터의 다른 노드들은 클라이언트에서는 보이지 않는다. (만약 둘 이상의 TCP 라우터 노드가 있는 경우, RR-DNS가 하나의 도메인 이름을 여러 TCP 라우터로 대응시킨다) 클라이언트는 요청을 TCP 라우터 노드로 보내고, 이 TCP 라우터 노드는 특정 TCP 연결에 속한 모든 패킷을 서버 노드들 중의 하나로 보낸다. TCP 라우터는 어느 노드로 라우팅 할 것인지 결정하기 위해 부하(load)에 기반한 다른 알고리즘을 사용할 수도 있고, 부하에 기반한 알고리즘보다 성능이 떨어지는 라운드-로빈 방법을 사용할 수도 있다. 서버 노드는 TCP 라우터를 건너뛰고 클라이언트에 직접 응답한다. 요구 패킷은 응답 패킷에 비하면 작기 때문에, TCP 라우터에는 작은 부하만 걸린다. TCP 라우터 스킴은 DNS 기반 솔루션보다 좋은 로드 밸런싱을 제공하고, 클라이언트나 네임 서버의 캐싱 문제를 피할 수 있다. 라우터는 개별 서버 노드의 부하를 고려한 더 좋은 로드 밸런싱 알고리즘을 사용할 수도 있다. TCP 라우터는 웹 서버 노드의 고장을 인식하여 사용자의 요청을 사용 가능한 웹 서버 노드로만 전송할 수 있다. 시스템 관리자는 TCP 라우터의 설정을 변경하여 웹 서버 노드를 추가, 삭제할 수 있고, 이를 통해 웹 서버 클러스터를 관리할 수 있다. 백업 TCP 라우터를 설정하여, TCP 라우터 노드의 고장을 처리할 수 있고, 백업 라우터는 정상 동작시에는 웹 서버로 동작할 수 있다. 1차 TCP 라우터의 고장을 인식하면, 백업 라우터는 클라이언트의 요청을 자신을 제외한 남아있는 웹 서버 노드로 전송한다. “ 1998 동계 올림픽 웹 사이트의 구조는 1996년 하계 올림픽 웹 사이트에서의 경험에서 발전한 것이다. 1996년에 우리가 수집한 서버 로그로부터 1998년 웹 사이트 설계의 중요한 통찰을 얻을 수 있었다. 우리는 대부분의 사용자가 기본적인 정보, 메달 순위, 최근의 결과, 현재 뉴스 등을 찾기 위해 너무나 많은 시간을 소비한다는 것을 알게 되었다. 클라이언트는 최소한 세 번 이상의 웹 서버 요청을 통해서야 결과 페이지에 도달할 수 있었다. 사이트의 뉴스, 사진, 스포츠 섹션 등에 대해서도 비슷한 브라우징 패턴을 보였다. 더 나아가, 한 클라이언트가 한 마지막 페이지에 도착하고 나면, 거기엔 다른 섹션에 있는 적절한 정보로 이동하는 직접 링크가 아무 것도 없었다. 이 계층적 탐색 순서 때문에, 중간에 탐색되는 페이지들은 가장 자주 접근되는 것들에 포함되었다.1998 사이트의 주요 목표 중의 하나는 히트 수 감소였는데, 1996년의 웹 사이트 디자인과, 1998 사이트에서 제공되는 추가된 컨텐츠를 고려하여 예측하면 하루 2억 히트 이상을 기록하기 때문이었다. 따라서 우리는 페이지를 재설계하여 클라이언트가 관계된 정보들을 더 적은 수의 웹 페이지를 보면서 얻을 수 있도록 하였다. 1998 올림픽 게임 웹 사이트의 자세한 설명은 이전의 연구에서 얻을 수 있다. 가장 중요한 변화는 매일 새로운 홈페이지를 생성하고, 이전의 홈 페이지를 클라이언트들이 볼 수 있도록 하는 최상위의 탐색 레벨을 추가한 것이었다. 우리 예상으로는 개선된 페이지 설계로부터 3배 이상의 히트 수 감소를 얻을 수 있었다. 웹 서버 로그 분석에 의하면 25%의 사용자는 개선된 홈페이지에서는 그날의 홈페이지 하나만 보면 원하는 정보를 찾을 수 있었다. ”위에서 볼 수 있듯이 고성능 서버의 구현은 전체적인 시스템 설계, 로드밸런싱과 같은 구현 기법, 그리고 웹 사이트의 구축 과정에서의 튜닝 등 다양한 요소가 성공적으로 결합될 때 이루어질 수 있다. 필자가 번역한 전체 문서는 국내의 검색 엔진에서 ‘고성능 웹 사이트 검색 기법’이라는 문서를 찾아보기 바란다.</IBM의 올림픽 사이트 관련>
2. 리눅스 로드 밸런싱 솔루션 (1) 리눅스 가상 서버 LVS (Linux Virtual Server) 리눅스 가상 서버 LVS 프로젝트의 홈페이지는 http://www.linuxvirtualserver.org이다. LVS(Linux Virtual Server)는 중국의 Wensong Zhang에 의해서 시작되었다. LVS의 기본적인 아이디어는 IBM에서 유래한 것이며, 애틀란타 올림픽과 시드니 올림픽과 같이 하루 동안 최대 접속이 10억번에 가까운 사이트의 구성을 위해 활용되었다. IBM은 이와 관련한 몇 개의 특허를 갖고 있다. LVS 프로젝트는 그 이전부터 개발되어 오고 있던 HA Linux project를 활용하고 있으며 HA Linux 프로젝트는 mon, fake 등을 사용하고 있다. http://www.linux-ha.org 사이트에서 heartbeat 등의 패키지를 구할 수 있다. (HA Linux 프로젝트와 LVS 프로젝트, RedHat의 Piranha 패키지는 오픈 소스의 진화적인 발전 과정을 잘 보여준다고 생각한다. 이전의 상업적인 소프트웨어 개발 모델의 경우, 같은 이론이나 알고리즘을 사용하더라도 소스 코드의 활용이나 라이브러리화가 거의 이루어지지 못했는데, 오픈 소스 프로젝트에서는 다른 프로젝트의 소스 코드를 활용하는 것이 오히려 일반적이라고 할 수 있다.) LVS에서 HA Linux 프로젝트는 Active-Passive 설정에서 상대편 서버가 정상적으로 동작하는지 판단하기 위해 사용되며, mon은 실제 서버 노드의 부하 수준을 판단하기 위해 사용된다. 이와 유사한 기본 아이디어를 갖고 있는 솔루션으로는 RedHat의 Piranha, Ultra Monkey, Turbo Linux의 Cluster 등이 있다. RedHat의 Piranha는 LVS를 바탕으로 재구성하고 기능을 추가한 패키지이다. Ultra Monkey의 경우 VA Linux에서 제시하고 있는 공개 솔루션으로서 LVS를 바탕으로 하고 있다. 터보 리눅스의 클러스터 서버도 기본 아이디어는 유사한데, 새로 구현된 코드로 구성되어 있다. 터보리눅스의 클러스터 서버는 설치되는 서버 노드의 수에 따라 비용을 지불해야 하는 상용 제품이다. 1) 로드밸런싱의 구조 로드밸런싱을 위한 구조는 다음과 같이 몇 가지 설정이 가능하다.
NAT는 사용자의 요청 패킷과 실제 서버의 응답 패킷이 모두 로드밸런서를 거치는 구조이다. 실제 서버에 다양한 OS를 사용할 수 있지만, 확장성이 좋지 못하다. IP 터널링은 로드밸런서와 실제 서버에 모두 IP 터널링을 처리할 수 있는 커널이 설치되어 있어야 한다. 시스템 설정은 유연하게 할 수 있다. 터널링을 위한 패킷변환 부하가 약간 증가한다. Direct Routing은 시스템 설정의 제약이 있으나, 높은 성능을 얻을 수 있다. 로드밸런싱 구조의 선택은 시스템 설정이 모두 끝난 다음 이루어지는 것이 아니라, 시스템의 용도에 따라 시스템 설정 이전에 선택해야 한다.
<패킷의 변환> 패킷 변환은 다음과 같이 동작한다. 입력 패킷의 출발 주소와 도착주소가 다음과 같다고 하자. SOURCE 202.100.1.2:3456 DEST 202.103.106.5:80 로드밸런서는 실제 서버를 선택한다. 예를 들어 172.16.0.3:8000을 선택했다고 하면 패킷을 다음과 같이 변환하여 서버로 전송한다. SOURCE 202.100.1.2:3456 DEST 172.16.0.3:8000 응답 패킷은 로드밸런서에 다음과 같이 돌아온다. SOURCE 172.16.0.3:8000 DEST 202.100.1.2:3456 패킷은 원래의 가상 서버 주소에서 돌아오는 것처럼 보이기 위해 다시 다음과 같이 변환된다. SOURCE 202.103.106.5:80 DEST 202.100.1.2:3456 NAT는 패킷을 변환하여 실제 서버에 전달하고, 실제 서버에서 돌아오는 응답 패킷은 다시 NAT를 거쳐서 사용자에게 전달된다. NAT가 양방향 패킷에 대해서 모두 처리하므로 실제 서버에 임의의 OS를 사용할 수 있어서 응용 분야가 넓지만, 일반적으로 사용자의 요청 패킷에 비해서 실제 서버에서 돌아오는 응답 패킷의 크기가 훨씬 크기 때문에 (웹 서버의 경우, 사용자의 요청 패킷은 URL 요청으로 구성되지만, 실제 서버의 응답 패킷은 해당 URL에 대한 HTML 문서이다) NAT를 거쳐 가는 네트워크 패킷의 부하가 증가한다. 따라서 실제 서버가 10 노드 이하인 경우에만 NAT를 쓰는 것이 바람직하다. NAT의 장점은 실제 서버에 임의의 OS를 사용할 수 있다는 것이고, 단점은 확장성이 떨어진다는 것이다.
<시스템 그림>
<패킷의 변환>
IP 터널링(Tunneling)은 로드밸런서가 사용자의 요청 패킷을 실제 서버에 전달하기 위해 다른 패킷 구조로 한겹 씌워서 실제 서버에 전달하면, 실제 서버가 새로운 패킷에서 사용자의 요청 패킷을 꺼내서 처리하는 방식이다. 따라서 IP 터널링은 실제 서버의 커널도 요청 패킷을 처리하기 위해 터널링을 지원해야만 하는 구조이다. 그러므로 리눅스로 전체 시스템을 설정하게 된다. 실제 서버의 응답 패킷은 이더넷 스위치를 거쳐서 바로 사용자에게 전달된다. 다음에 설명하는 직접 라우팅(Direct Routing) 보다 좋은 점은, 실제 서버가 IP 터널링을 지원하기만 하면 실제 서버는 지리적으로 멀리 떨어져 있어도 인터넷 상에서 연결되어 있기만 하면 된다는 것이다. 따라서 WAN 환경에서 로드밸런싱을 설정할 경우 IP 터널링을 고려할 수 있다. IP 터널링의 장점은 확장성이 좋고(100 노드 정도까지), 실제 서버의 위치나 네트워크 연결의 제약이 적다는 것이며, 단점은 실제 서버에서 IP 터널링을 지원하도록 커널이 설정되어 있어야 한다는 것이다.
<시스템 그림> 직접 라우팅(Direct Routing)의 시스템 구조는 앞의 IP 터널링과 동일하다. 그렇지만, 로드밸런서와 실제 서버는 반드시 동일한 물리적 세그먼트에 존재해야 한다. 직접 라우팅은 이더넷의 브로드캐스팅을 사용하기 때문이다. <패킷의 변환>
직접 라우팅은 로드밸런서와 실제 서버를 물리적으로 같은 네트워크 세그먼트에 위치시키고, 이 특성을 활용하여 IP 터널링처럼 패킷을 덧씌우는 것이 아니라, 단지 패킷의 MAC 어드레스를 목적지 주소로 변경시킨 다음 실제 서버로 전달하는 방식을 사용한다. 실제 서버는 IP 터널링의 패킷 변환 부하도 없으며, 실제 서버의 응답 패킷은 이더넷 스위치를 거쳐서 바로 사용자에게 전달된다. 직접 라우팅의 장점은 확장성이 좋고(100 노드 정도까지), IP 터널링을 처리하기 위한 오버헤드도 없다는 점과, 실제 서버에 특별한 설정이 필요하지 않다는 점이다. 단점은 로드 밸런서와 실제 서버가 물리적으로 같은 네트워크 세그먼트에 속해 있어야 한다는 점이다. 2) 스케줄링 알고리즘 또한 스케줄링을 위해 다음과 같은 몇 가지 알고리즘을 적용할 수 있다. 스케줄링 알고리즘은 앞의 로드밸런싱 구조에 달리 시스템 설정이 끝난 다음에도 알고리즘을 변경할 수 있다.
라운드-로빈 방식은 로드밸런서에 들어오는 요청 패킷들을 차례대로 실제 서버에 할당하는 방식이다. 이 방식에서 실제 서버의 현재 부하 상황 등은 고려되지 않는다. 단지 차례대로 할당할 뿐이다. 하지만, 이렇게 하더라도 로드밸런싱을 위해 이전에 사용되던 라운드-로빈 DNS 방식에 의해 서버를 할당하는 방식에 비해서는 우수한데, DNS의 경우는 한번 서버가 지정되면 해당 서버에 수많은 요청 패킷이 몰릴 수 있기 때문이다. 가중 라운드-로빈 방식은 기본적으로 라운드-로빈 방식인데, 각 서버에 서로 다른 가중치를 주어서 할당하는 방식이다. 이 방식을 사용해야 하는 경우는 실제 서버들이 CPU의 수와 성능, 메모리 용량 등 서로 다른 성능을 가지고 있어서, 각 서버를 동등하게 취급할 수 없는 경우이다. 최소 연결 방식은 실제 서버들 중에서 현재 가장 적은 수의 요청을 처리하고 있는 서버를 선택하여 요청 패킷을 할당하는 방식이다. 이 방식은 실제 서버의 현재 부하 상황을 동적으로 판단하여 요청을 처리하기 때문에, 앞의 두 방식에 비해서 동적으로 우수한 부하 분산 효과를 얻을 수 있다. 가중 최소 연결 방식은 기본적으로 최소 연결 방식인데, 가중 라운드-로빈 방식과 마찬가지로 각 서버에 서로 다른 가중치를 주어서 할당하는 방식이다. 3) 설정 예제 NAT의 경우 웹 서버를 위한 간단한 설정 예는 다음과 같다. 다음 설정은 모두 로드밸런서에서 설정한다. 로드밸런서가 패킷 매스커레이딩을 처리하도록 하기 위해 다음과 같이 설정한다. echo 1 > /proc/sys/net/ipv4/ip_forward ipchains -A forward -j MASQ -s 172.16.0.0/24 -d 0.0.0.0/0 그리고 웹 서버를 설정하는 경우, 가상 서버의 80 포트에 대해 스케줄링 알고리즘을 설정한다. wlc는 가중 최소 연결 방식을 나타낸다. ipvsadm -A -t 202.103.106.5:80 -s wlc 그리고 로드밸런서에 실제 서버를 다음과 같이 추가한다. ipvsadm -a -t 202.103.106.5:80 -R 172.16.0.2:80 -m ipvsadm -a -t 202.103.106.5:80 -R 172.16.0.3:8000 -m -w 2 그러면 좀 더 자세히 설정을 알아보도록 하자. 패킷 매스커레이딩을 설정하는 것은 위에서 설정한 내용으로 충분하다. 다음으로, 스케줄링 알고리즘의 설정은 로드밸런서 설정 과정에서 ipvsadm에서 -s 옵션을 사용하여 설정한다. 다음 예제는 rr(round robin)으로 설정한 경우이고, wrr(weighted round robin), lc(least-connection), wlc(weighted least-connection) 옵션을 사용할 수 있다. ipvsadm -A -t 207.175.44.110:80 -s rr 그 다음으로 실제 서버를 다음과 같이 설정한다. ipvsadm -a -t 207.175.44.110:80 -r 192.168.10.1 -m ipvsadm -a -t 207.175.44.110:80 -r 192.168.10.2 -m ipvsadm -a -t 207.175.44.110:80 -r 192.168.10.3 -m ipvsadm -a -t 207.175.44.110:80 -r 192.168.10.4 -m ipvsadm -a -t 207.175.44.110:80 -r 192.168.10.5 -m 직접 라우팅 설정의 경우 다음과 같이 설정한다. 시스템이 사용하고 있는 주소는 172.26.20.xxx이고, 여기에서 로드밸런서의 주소는 111번, 실제 서버의 주소는 112번 이후, 그리고 가상 서버의 주소는 110번이다. 로드밸런서의 경우는 다음과 같이 설정한다. ifconfig eth0 172.26.20.111 netmask 255.255.255.0 broadcast 172.26.20.255 up route add -net 172.26.20.0 netmask 255.255.255.0 dev eth0 ifconfig eth0:0 172.26.20.110 netmask 255.255.255.255 broadcast 172.26.20.110 up route add -host 172.26.20.110 dev eth0:0 echo 1 > /proc/sys/net/ipv4/ip_forward ipvsadm -A -t 172.26.20.110:23 -s wlc ipvsadm -a -t 172.26.20.110:23 -r 172.26.20.112 -g 실제 서버 1번에서 다음과 같이 설정한다. 다른 실제 서버의 경우 112를 113, 114 등으로 변경해야 한다. ifconfig eth0 172.26.20.112 netmask 255.255.255.0 broadcast 172.26.20.255 up route add -net 172.26.20.0 netmask 255.255.255.0 dev eth0 ifconfig lo:0 172.26.20.110 netmask 255.255.255.255 broadcast 172.26.20.110 up route add -host 172.26.20.110 dev lo:0 또는 숨은(Hidden) 디바이스를 사용하여 다음과 같이 설정할 수도 있다. 로드밸런서에서 다음과 같이 설정한다. echo 1 > /proc/sys/net/ipv4/ip_forward ipvsadm -A -t 172.26.20.110:23 -s wlc ipvsadm -a -t 172.26.20.110:23 -r 172.26.20.112 -g 그리고 실제 서버에서 다음과 같이 설정한다. echo 1 > /proc/sys/net/ipv4/ip_forward ifconfig lo:0 172.26.20.110 netmask 255.255.255.255 broadcast 172.26.20.110 up route add -host 172.26.20.110 dev lo:0 echo 1 > /proc/sys/net/ipv4/conf/all/hidden echo 1 > /proc/sys/net/ipv4/conf/lo/hidden LVS를 직접 사용하는 경우의 자세한 설명은 LVS Documentation (http://www.linuxvirtualserver.org/Documents.html)을 참조하기 바란다.
(2) 레드햇의 피라냐 (RedHat Piranha) 레드햇의 피라냐(piranha) 패키지는 LVS를 바탕으로 하여 재구성한 패키지로서 다음과 같은 세 개의 패키지로 구성되어 있다. piranha 피라냐의 기본 패키지 piranha-docs 피라냐의 문서 패키지 piranha-gui 피라냐의 GUI 패키지 (piranha-gui 패키지의 경우, 피라냐 설정을 X 터미널을 통해서나 웹을 통해 원격으로 관리할 수 있도록 해 주는데, 이전의 패키지에서 기본 패스워드를 설정한 채로 출시되어 문제가 된 적이 있다. 현재는 piranha-gui 패키지를 선택한 다음 패스워드를 설정해 주는 프로그램인 piranha-passwd을 사용하여 원격 관리를 위한 패스워드를 설정하도록 하고 있다) 레드햇의 피라냐 패키지는 레드햇 6.x 버전의 경우는 기본 패키지에 포함되어 있었고, 7.x의 경우는 레드햇 ftp 사이트에서 구할 수 있다. 피라냐의 핵심은 로드밸런서 두 개 노드에서 동작하는 lvs와 pulse, 그리고 실제로 작업을 처리하는 실제 서버에서 동작하는 nanny 데몬으로 구성되어 있다. lvs는 로드밸런서에서 사용자의 요청 패킷을 실제 서버에 분배하는 역할을 수행하며 pulse에 의해 실행된다. pulse는 로드밸런서가 정상적으로 동작하고 있는지 여부를 백업 로드밸런서가 알 수 있도록 하기 위해 사용된다. 그리고 nanny 데몬은 실제 서버와 로드밸런서에서 서로 다른 옵션을 사용하여 실행되는데, pulse에 의해 서버들의 상태를 모니터하기 위해 사용되는 데몬이다. ntsysv에서 pulse 서비스를 선택함으로써 로드밸런서를 설정할 수 있다. 이렇게 설정함으로써, 로드밸런서가 매번 리부팅될 때마다 pulse 데몬이 실행되며, pulse 데몬이 실행되면 lvs 데몬과, fos 데몬이 실행되고, lvs 데몬은 nanny 데몬을 실행시킨다. 피라냐의 설정은 /etc/lvs.cf 설정 파일과, ipvsadm 관리 프로그램을 통해 이루어진다. 웹을 통해 설정할 수도 있지만, 웹을 통해 이와 같은 로드밸런싱 시스템을 설정하는 것 보다는 설정 파일을 사용하여 설정하는 것이 좋을 것 같다. /etc/lvs.cf는 다음과 같은 세 부분으로 구성되어 있다.
다음은 sample.cf라는 샘플 화일에서 뽑은 것이다.
service = lvs primary = 207.175.44.150 backup = 207.175.44.196 backup_active = 1 heartbeat = 1 heartbeat_port = 1050 keepalive = 6 deadtime = 18 두 개의 로드밸런서 서버의 IP 주소를 설정하고, 백업 로드밸런서가 있으므로 backup_active를 1로 설정하며, heartbeat를 사용할 것이므로 heartbeat를 1로 설정한다.
virtual server1 { address = 207.175.44.252 eth0:1 active = 1 load_monitor = uptime timeout = 5 reentry = 10 port = http send = "GET / HTTP/1.0\r\n\r\n" expect = "HTTP" scheduler = wlc persistent = 60 pmask = 255.255.255.255 protocol = tcp server Real1 { address = 192.168.10.2 active = 1 weight = 1 } server Real2 { address = 192.168.10.3 active = 1 weight = 1 } } 가상 서버의 주소는 207.175.44.252이고, 실제 서버의 주소는 192.168.10.2, 192.168.10.3 등이다. port=http는 port=80과 같이 쓸 수도 있다.
failover ftp { active = 0 address = 207.175.44.252 eth0:1 port = 21 send = "\n" timeout = 10 start_cmd = "/etc/rc.d/init.d/inet start" stop_cmd = "/etc/rc.d/init.d/inet stop" } 위의 예는 ftp에 대한 failover 설정이며, 21번 포트에 대해 설정하고 있다. ipvsadm은 LVS 패키지에서 바뀐 것이 거의 없다. 그리고 레드햇의 피라냐 패키지에서는 lvs.cf를 통해 시스템을 설정하도록 하고 있으므로, ipvsadm을 사용하지 않는 것이 바람직하다.
(3) 기타 상용 솔루션 1) Resonate Resonate사의 홈페이지는 http://www.resonate.com이다. Resonate는 상용 로드 밸런싱 솔루션을 공급하는 회사로서 Resonate Central Dispatch와 Resonate Global Dispatch 등의 로드 밸런싱 솔루션을 제공한다. Resonate Central Dispatch는 LAN 기반의 로드밸런싱 솔루션으로서, 기본적으로 LVS나 이를 바탕으로 한 RedHat Piranha 솔루션과 유사하다. Resonate Global Dispatch는 WAN 기반의 로드밸런싱 솔루션으로서, 지역적으로 분산된 광역 시스템 설정을 위한 솔루션이다. 2) PolyServe underSTUDY PolyServe사의 홈페이지는 http://www.polyserve.com이다. PolyServe는 underSTUDY라는 상용 로드 밸런싱 솔루션을 공급하는 회사이다. 현재는 LocalCluster enterprise라는 제품명으로 바뀌었다.
3. 리눅스 고가용성 솔루션 (1) 리눅스 고가용성 솔루션의 개요 1) 고가용성(High Availability) 클러스터란? 엔터프라이즈 컴퓨팅 환경에서 24 x 7 서비스란 1년에 시스템의 정지시간이 수분에서 1시간 이내여야만 한다. 이와 같은 무정지 서비스를 가능하게 해주는 클러스터를 고가용성(High Availability) 클러스터라고 한다. 고가용성 클러스터는 일반적으로 폴트 톨러런트(Fault Tolerant) 시스템과는 달리 보편적인 하드웨어와 네트웍 장비, 스토리지, UPS등으로 구성되며 서비스의 예정된 중단 혹은 불시의 중단에 의한 중단 시간(downtime)을 최소화하여 서비스 중단으로 인한 비용 손실을 최소화하도록 구성된다. 두대의 시스템이 Active-active (각각의 노드가 각각 서비스를 수행) 혹은 Hot-standby(한 노드가 서비스를 수행하고 다른 노드가 standby 상태로 대기) 형태로 구성되며 서비스중에 문제가 발생하거나(unplanned outages) 혹은 서비스 업그레이드 등을 위한 예고된 시스템 정지(planned outages)시 정지된 서버에서 가동되던 서비스가 나머지 노드로 fail-over 하도록 구성된다. 2) 고가용성(High Availability) 로드밸런싱 클러스터는 기본적으로 성능을 높이기 위한 클러스터이다. 그러나 여기서도 서비스 노드가 정상적으로 동작하지 않는 경우 해당 노드를 제외함으로써 전체적인 서비스를 계속하도록 한다. 반면에 로드 밸런서의 경우 하나의 서버의 오동작으로 인해 전체 시스템의 서비스 중단을 일으킬 수 있으므로, 이 경우에 대해 로드 밸런서를 중복시켜 문제를 해결할 수 있다. 로드 밸런서 두 개가 모두 오동작 하는 경우에 대해 이론적으로는 다른 서비스 노드들이 로드 밸런서의 역할을 이어받아 하도록 설정할 수 있으나, 실제 서비스 상황에서 이런 설정은 불필요한 경우가 대부분이다. RAID 스토리지의 경우에도 하나의 디스크의 오류에 대해서 고려하는 것과 마찬가지이다.
(2) Kimberlite/Convolo 클러스터 미국의 Mission Critical Linux 사에서 Active-Passive HA 솔루션을 두 가지 버전으로 제공하고 있다. Kimberlite는 소스가 공개되어 있는 GPL 버전이고, Convolo는 상용 버전이다. 이 회사의 홈 페이지는 http://www.missioncriticallinux.com이며, GPL 버전인 Kimberlite는 http://oss.missioncriticallinux.com/projects/Kimberlite 에서 받을 수 있다. 이들 클러스터는 데이타베이스 백엔드 등과 같이 저장 장치를 공유하는 경우에 적합하다. 예를 들어 MySQL, Oracle, NFS 등에 대해서 HA 솔루션을 제공하고자 하는 경우이다. 1) 하드웨어 설정 다른 클러스터와 마찬가지로, Kimberlite 클러스터의 경우에도 다음 그림과 같이 기본적인 시스템 설정이 중요하다. 기본적인 시스템 설정이 구성된 다음에 소프트웨어를 설치하고 소프트웨어적인 설정을 하게 된다.
두 서버 노드는 시스템의 상태를 저장하기 위해 quorum이라는 공유 디스크 파티션을 사용하고, 상대방의 상태를 검사하기 위해 이더넷, 시리얼 라인을 모두 사용한다.
2) 소프트웨어 설정 Kimberlite 패키지를 http://oss.missioncriticallinux.com/projects/Kimberlite/download.php에서 다운로드한 경우, Kimberlite 패키지는 소스 코드의 형태로만 배포되므로, 직접 빌드를 해야 한다. 빌드를 하기 위해서는 먼저 http://www.swig.org에서 swig 패키지를 받아서 설치해야 한다. (swig은 simplified wrapper and interface generator의 약어이다) swig 홈페이지의 다운로드 페이지를 보면 여러 버전이 있는데, stable release를 설치해야 한다. 압축을 풀고, ./configure, make, make install 과정을 거쳐서 swig을 설치한다. swig이 설치되고 나면 Kimberlite 패키지의 압축을 풀고, ./configure를 실행한 다음 make 하고, make install 하면 설치가 끝난다. 쉽게 설치가 될 수도 있고, 그렇지 않을 수도 있다. swig1.1p5와 Kimberlite-1.1.0을 받아서 빌드했다면 잘 설치될 것이다. Kimberlite는 /opt/cluster에 설치된다. 위의 그림과 같이 시스템을 설정하고, 소프트웨어를 설치하고 나면, Kimberlite 패키지를 설정하여 사용할 수 있다. 클러스터의 설정은 member_config 프로그램을 사용하여 이루어진다. 이 프로그램은 사용자가 어떤 정보를 입력해야 하는지 자세히 설명하고 있으므로, 쉽게 설정할 수 있을 것이다. 설정 내용을 간단히 요약하자면, 파워 스위치를 포함하고 있는지 여부, 클러스터 멤버의 이름, 상대편 시스템의 상태를 검사하기 위해 시리얼, 이더넷 등의 heartbeat를 몇 가지 사용할 것인지, 두 개의 quorum 파티션을 위한 raw 디바이스의 이름, 파워 스위치가 연결된 시리얼 라인 등이며, 먼저 자신의 시스템의 설정을 입력한 다음, 상대방 시스템의 설정을 입력해야 한다. 한 노드에서 member_config의 실행이 끝나고 나면, 다른 노드에서도 member_config을 실행시켜 주어야 한다. 새로운 노드에서 member_config을 실행하기 전에, 새로운 노드에서 다음과 같은 명령을 실행시켜 준다. # /opt/cluster/bin/clu_config --init=/dev/raw/raw1 그리고 나서 새로운 노드에 대해서도 자신의 설정과 상대방의 설정을 순서를 바꾸어 입력해 준다. 이렇게 해서 모든 설정이 끝나고 나면, 다음 명령을 사용하여 클러스터를 실행한다. # /etc/rc.d/init.d/cluster start 다음으로는 클러스터의 관리를 위해서 사용할 수 있는 명령들을 정리해 보도록 하자. 이들 명령은 모두 /opt/cluster/bin에서 찾을 수 있다. diskutil : quorum 파티션의 설정 상태를 볼 수 있다. pswitch : 파워 스위치의 설정 상태를 볼 수 있다. cluadmin : 명령 방식으로 HA 클러스터를 관리할 수 있는 도구이다. 이 명령에서 지원하는 기능은, 서비스의 추가, 변경, 삭제, 그리고 서비스의 활성화/비활성화, 클러스터와 서비스의 상태 보기, 클러스터 데이타베이스의 백업과 복구 등이다. cluadmin을 실행시키면, 다음과 같은 프롬프트를 볼 수 있다. cluadmin> 이 프롬프트에서 help 명령을 사용함으로써 도움말을 볼 수 있으며, clear는 화면을 지우는 명령, exit는 프로그램을 종료하는 명령이다. cluster에 대한 명령과 service에 대한 명령은 각각 cluster와 service 명령으로 시작하며, 다음과 같은 명령들이 있다. cluster status 클러스터의 상태를 보여준다. monitor 클러스터의 상태를 5초 간격으로 보여준다. loglevel 데몬에 대해 로그를 어떤 수준으로 남길 것인지 지정한다. reload 데몬들이 변경된 클러스터 설정 화일을 다시 읽도록 한다. name 클러스터의 이름을 변경한다. backup 클러스터 설정 데이터베이스를 백업 파일에 저장한다 restore 클러스터 설정 데이터베이스를 백업 파일에서 읽어들여 복구한다. saveas 클러스터 설정 데이터베이스를 지정한 파일에 저장한다. restorefrom 클러스터 설정 데이터베이스를 지정한 파일에서 읽어들여 복구한다. Service add 클러스터 데이터베이스에 클러스터 서비스를 추가한다. modify 지정된 서비스에 대한 자원이나 속성 등을 변경한다. show state 모든 서비스 또는 지정한 서비스의 현재 상태를 보여준다. show config 지정한 서비스의 현재의 설정을 보여준다. disable 지정한 서비스를 중단한다. enable 지정한 서비스를 시작한다. delete 지정한 서비스를 클러스터 설정 데이터베이스에서 삭제한다. 웹을 통해 시스템 설정을 모니터하거나, 변경할 수도 있는데, GPL 버전인 Kimberlite의 경우는 시스템 설정의 모니터 기능만 제공한다. /opt/cluster/clumon 디렉토리를 웹 서버에서 참조할 수 있는 디렉토리로 옮기고, 이 디렉토리의 clumon.cgi 프로그램을 사용하여 시스템 설정을 모니터할 수 있다. 상용 버전인 Convolo의 경우는 웹을 통해 시스템 설정을 변경할 수도 있다. 현재 Kimberlite 패키지에서 기본적으로 사용할 수 있는 서비스는 Oracle, MySQL, NFS, Apache, IBM DB2 등이다. 예제 디렉토리인 /opt/cluster/doc/services/examples에서 Oracle과 MySQL을 위한 설정 파일을 볼 수 있으며, 다른 서비스에 대해서는 다음 문서를 참조할 수 있다. 오라클의 경우는 /opt/cluster/doc/services/examples/oracle/oracle 파일을 /etc/rc.d/init.d에 서비스로 등록하여 사용하면 되고, MySQL의 경우는 /opt/cluster/doc/services/examples/mysql.server를 서비스로 등록하여 사용하면 된다. Kimberlite 패키지의 설정을 위한 가장 충실한 문서는 Kimberlite 패키지 안의 doc 디렉토리의 HTML 문서이다. 자세한 내용은 이 문서를 참조하기 바란다.
(3) OPS (Oracle Parallel Server) 1) 오라클 병렬 서버 OPS 오라클은 1998년 가을, 오라클 8 버전을 리눅스로 포팅한 제품을 발표한 이래, 오라클 8i, 오라클 8i Release2 등의 제품에 대해 리눅스 버전을 꾸준히 공급하고 있다. 오라클의 리눅스 버전은 리눅스 커널과 glibc 라이브러리 버전에만 의존하므로, 호환성은 좋은 편이다. (오라클의 리눅스 버전은 다른 유닉스 환경으로 포팅하는 작업에 비해 짧은 시간에 이루어졌다고 실제 작업의 담당자가 인터뷰에서 밝힌 바 있다. 그리고, 현재 오라클에서 리눅스 버전을 지원하기 위한 인력도 100명을 넘어섰다고 한다. 또한, 오라클 내부에서는 인텔 리눅스 버전 뿐만 아니라, 다른 아키텍처, 즉 Compaq Alpha, Sun Sparc 등의 아키텍처에서 동작하는 리눅스를 위한 오라클 버전도 사용중이라고 한다. 그리고, 인텔에서 발표할 Itanium (IA-64) 64bit CPU를 위해서도 리눅스와 윈도우 64에서 동작하는 오라클의 베타 버전을 http://technet.oracle.com에서 얻을 수 있다. 그러나 이 오라클 베타 버전은 너무 오래된 Itanium 버전의 베타 리눅스 배포판을 대상으로 했기 때문에, 최근의 리눅스 베타 버전에는 설치되지 않았다.) 그리고 가장 최근의 Oracle 8i Release 3(Oracle 8.1.7)의 경우는 오라클 병렬 서버(OPS, Oracle Parallel Server)를 포함하고 있다. 국내 시장에서는 유닉스 시장에서 특히 오라클의 시장 점유율이 높은데(시장이 작기 때문에 1위 제품에 비해 다른 제품에 대해서 기술 지원이 충분히 이루어지지 못하기 때문인 것 같다), 앞에서 설명한 Kimberlite 클러스터나 OPS를 사용하면 상대적으로 저렴한 가격에 다른 상용 유닉스 제품에 못지 않은 가용성을 제공할 수 있다. OPS를 사용하여 백엔드 데이타베이스를 Active-Active HA 클러스터의 형태로 구축할 수 있다. 물론 OPS를 사용하는 경우 두 대의 컴퓨터에 대해서 뿐만 아니라, 세 대 이상의 컴퓨터에 대해서도 HA 클러스터의 구축이 가능하다. Active-Passive 설정에 비해서 두 서버를 모두 서비스에 사용할 수 있다는 장점이 있으나, 두 서버 모두 오라클 엔터프라이즈 라이센스가 필요하며(Active-Passive 설정의 경우는 라이센스 하나로 충분하다), Active-Passive 설정에 비해 두배까지의 성능을 얻기는 어렵기 때문에, 앞의 설정에 비해 반드시 더 좋은 가격대 성능비를 제공한다고 말하기는 어렵다.
그림에서 보는 것처럼 오라클 병렬 서버는 분산 락 매니저(Distributed Lock Manager, DLM) 소프트웨어가 중요한 역할을 수행하며, 디스크를 공유하는 구조로 되어 있다. 오라클의 http://technet.oracle.com에서 OPS를 검색함으로써 자세한 OPS 관련 자료들을 구할 수 있다. 2) OPS의 설치 http://technet.oracle.com/software/products/oracle8i/software_index.htm 에서 Oracle 8i R3의 개발용 버전을 얻을 수 있으며, 설치 가이드도 얻을 수 있다. 오라클의 OPS는 디스크 공유 구조로 설계되어 있으며, 따라서 시스템의 기본적인 하드웨어 구성은 앞에서 설명한 Kimberlite 클러스터와 유사하다. OPS는 두 개 이상의 서버와, 이들 서버에서 모두 공유하고 있는 디스크 장치로 구성된다. OPS를 설치하기 위해서는 공유 디스크에 노드 모니터를 위한 raw 디바이스를 설정해야 한다. 리눅스에서 raw 디바이스의 설정은 raw 명령을 사용하여 하드디스크 파티션에 대해 일종의 링크를 생성하는 방법으로 이루어진다. 그리고 watchdog 서버를 설정해야 하며, rsh과 rcp를 위해 /etc/hosts.equiv 파일을 설정하여 서버 노드 사이에서 패스워드 검사 없이 다른 노드에서 명령을 실행할 수 있도록 해야 한다. 오라클 설치과정에서 root.sh을 실행하는 과정이 있는데, OPS 설치 과정에서 각 서버 노드에서 이 스크립트를 실행해 주어야 한다. OPS의 설치를 위해서는 오라클 설치 프로그램에서 Enterprise Edition을 선택하고, 설치 타입은 Custom을 선택하며(Typical에서는 OPS를 선택할 수 없다), Available Products에서 Oracle Parallel Server를 선택하여 설치한다. 설치 과정에서 OPS에 참여하는 원격 노드들의 노드 이름을 입력해 주어야 한다. 설치가 끝나고 나면, OPS에 참여하는 각 서버 노드에서 OCMS(Oracle Cluster Management Software)를 실행시켜 주어야 하며, 그 다음으로 설치 프로그램을 실행시킨 서버에서 dbassist와 netca를 실행시켜 데이터베이스와 네트워크를 설정한다. * 오라클 병렬 서버 OPS는 오라클 8i Release 3에 포함되어 있지만, 별도의 라이센스를 요구하는 패키지이므로, technet에서 다운로드 받아서 사용하는 것은 개발 및 테스트용에 한정된다.
(4) SteelEye
LifeKeeper 솔루션은 여러 노드로 구성된 시스템에서 가용성을 보장하기 위한 failover 기능을 다양한 시스템 연결 모델에 대해서 제공하고 있다. LifeKeeper 솔루션도 TCP, TTY, 공유 디스크 등 다양한 연결을 사용하여 상대 서버가 살아 있는지 계속 확인하며, N+1 설정에서 특정 서비스에 대한 자신의 상대 서버가 정상적으로 동작하지 않는 경우 해당 서비스에 대해서 서비스를 이전받아서 계속 서비스하는 구조이다. 자세한 내용은 LifeKeeper for Linux 페이지를 참조하기 바란다. 또한 LifeKeeper 솔루션은 MySQL, Informix, Oracle, Sendmail, Apache, Print 서비스에 대해서 recovery kit을 제공하고 있다. SteelEye사의 홈페이지에서 특히 LifeKeeper Tutorial의 슬라이드를 보면 LifeKeeper에 대해 잘 설명하고 있으므로 참조하기 바란다. 필자의 판단으로는 Mission Critical Linux에서 제공하는 Kimberlite/Convolo 클러스터에 비해 SteelEye의 솔루션이 더 많은 기능을 제공하는 솔루션임은 분명하다. 그렇지만, Mission Critical Linux의 솔루션으로 충분한 응용에 대해서는 Mission Critical Linux의 솔루션이 더 가볍고 깨끗한 솔루션이라는 생각이다. 물론 비용 측면에서도 상대적으로 저렴하고, GPL 버전을 사용할 수도 있다. 두 제품 모두 훌륭하지만, 사용 목적에 따라서 선택해야 할 것이라고 생각한다.
4. 프로세스 마이그레이션 2장에서 살펴본 로드밸런싱은 사용자의 요청을 적절히 분산시켜 줌으로써 여러 서버 노드에 부하를 분산시키는 기법이다. 따라서 사용자의 요청이 빈번하며, 각 요청이 오래 실행되지 않는 응용의 경우에 바람직하다. 그러나, 사용자의 요청이 그렇게 많지 않고, 각 요청이 상대적으로 오래 실행되는 경우, 특정 노드에만 여러 프로세스가 실행되고 있을 때, 이를 다른 노드로 옮김으로써 로드밸런싱을 이룰 수 있다. (1) 프로세스 마이그레이션 개요 프로세스 마이그레이션은 한 컴퓨터에서 너무 많은 작업이 실행중일 때, 로드 밸런싱을 위해 프로세스를 현재 많은 작업을 실행하고 있지 않은 다른 컴퓨터로 이동시키는 기법이다. 즉, 프로세스를 정적으로 처리하지 않고, 사용자의 요청에 따라 동적으로 할당할 뿐만 아니라, 프로세스가 실행 중에 다른 서버로 이동할 수 있다. 2장에서 살펴본 로드밸런싱 기법은 사용자의 요청을 처리하기 위한 프로세스를 어떤 서버에서 실행할지 결정하고 나면 실행이 끝날 때까지 해당 서버에서 프로세스가 실행되는 것에 비해서, 프로세스 마이그레이션에서는 프로세스가 실행 중에 다른 서버로 이동하는 것이기 때문에 더 많은 기술적인 제약을 갖는다. 특히 프로세스가 이동할 때 현재 열려있는 파일이나 소켓등에 대해서 어떻게 처리할 것인가 하는 문제가 중요하다. 프로세스 마이그레이션을 위해서는 기본적으로 각 서버 노드가 파일 시스템 등 외부 환경에 대해 동일한 인터페이스를 제공해야 한다. 즉 서버 노드의 투명성을 제공해야 한다. 그 다음으로 프로세스가 마이그레이션될 때 프로세스 상태를 어떤 서버가 관리할 것인가의 문제가 있다. 프로세스 마이그레이션의 구현은 커널 수준 또는 사용자 수준에서 이루어질 수 있으며, 관리 방식도 중앙 집중식과 , 분산 제어 방식으로 구분된다. 현재 MOSIX, Condor, Sprite 등의 프로젝트가 있다.
(2) MOSIX MOSIX 프로젝트의 홈페이지는 http://www.mosix.cs.huji.ac.il/ 이다. MOSIX의 소스코드의 저작권은 GPL로 명시되어 있다. 이스라엘의 헤브루 대학에서 계속 연구되어 왔으며, 리눅스 버전은 버전 0부터 시작된 이 프로젝트의 버전 7이라고 한다. (홈페이지의 정보에 따르면 첫번째 버전은 PDP-11 상에서 1977년부터 1979년까지 개발되었다.) MOSIX의 적당한 응용 분야는 CPU 위주의 작업으로서 실행 시간이 긴 프로세스들로 구성된 작업에 적당하다. MOSIX의 프로세스 마이그레이션은 커널 패치가 필수적이며, ReiserFS, GFS 등과 같이 동작할 수 있다. GFS와 함께 사용할 때, MOSIX는 파일 I/O를 마이그레이션된 노드로 함께 이동시킬 수 있다. 현재 리눅스 버전에서 활발히 개발되고 있는 MOSIX는 커널 2.2.19에 대해 안정적인 버전이 있으며, 커널 2.4.3에 대해서 개발 버전이 나와 있는 상태이다. 1) MOSIX의 설치 MOSIX를 설치하기 위해서는 패키지를 받아서 풀고, README 파일에 따라서 설치하면 된다. 매뉴얼 파일은 manuals.tar, 사용자 프로그램은 user.tar 파일에 들어 있다. MOSIX의 클러스터 설정은 모든 노드가 동일하다. 수동으로 클러스터의 각 노드에 모두 설치할 수도 있고, 한 노드에 설치한 다음 클러스터의 모든 노드를 똑같이 복사해 주는 프로그램들을 사용할 수도 있다. 2.4.3 커널을 위한 개발 버전을 설치하는 경우, 먼저 일반 배포판을 설치하고, 2.4.3 커널의 소스 코드를 풀어서 여기에 MOSIX 패치를 적용한다. (배포판에 들어있는 소스 코드는 자체적인 패치를 너무 많이 포함하고 있기 때문에 MOSIX 패치가 잘 적용되기 힘들다) 패치를 적용한 다음에 빌드하는데, 레드햇 7.0의 경우는 들어있는 gcc 2.96을 사용하지 말고 kgcc를 사용해서 빌드하도록 한다. 커널을 빌드해서 설치하여 MOSIX 커널이 실행되도록 하고, user.tar의 사용자 프로그램을 설치하고 나면, mosix.init을 /etc/rc.d/init.d에 복사하고, 실행 레벨에 따라서 mosix.init을 실행하도록 다음과 같이 링크를 만들어 준다. MOSIX의 시작을 위한 링크 : ln -s /etc/rc.d/init.d/mosix /etc/rc.d/rc3.d/S95mosix ln -s /etc/rc.d/init.d/mosix /etc/rc.d/rc5.d/S95mosix MOSIX의 종료를 위한 링크 : ln -s /etc/rc.d/init.d/mosix /etc/rc.d/rc0.d/K05mosix ln -s /etc/rc.d/init.d/mosix /etc/rc.d/rc1.d/K05mosix ln -s /etc/rc.d/init.d/mosix /etc/rc.d/rc6.d/K05mosix 이와 같이 MOSIX를 설치하고 나면 클러스터는 부하가 많이 걸린 노드에 대해서 프로세스를 다른 노드로 마이그레이션 한다. 이 때 중요한 시스템 데몬에 대해서는 프로세스 마이그레이션을 막아 주어야 한다. 이를 위해 /etc/inittab에서 데몬을 실행하는 경우에 "/bin/mosrun -h"를 앞에 붙여 준다. 예를 들어 "/etc/rc.d/rc 3"를 "/bin/mosrun -h /etc/rc.d/rc 3"으로 바꿔준다. rc.sysinit, update, shutdown 등에 대해서도 마찬가지이다.
(3) Scyld scyld는 Beowulf 클러스터를 처음 만들어낸 Donald Becker (수많은 리눅스용 이더넷 드라이버의 개발자이기도 하다)가 Beowulf의 뒤를 이어 새로 내어 놓은 클러스터이다. (Scyld사에는 최근에 레드햇의 Robert Young이 경영진에 참여했다.) 홈페이지는 http://www.scyld.com이다. Scyld의 저작권은 GPL로 명시되어 있다. scyld에서도 MOSIX와 마찬가지로 프로세스 마이그레이션이 중요한 역할을 담당한다. Scyld Beowulf 클러스터는 실제 작업을 처리하는 서버 노드들과, 이들을 관리하는 마스터 노드로 구성되어 있으며, 패키지의 핵심은 BProc(Beowulf Distributed Process Space)이다. 작업 프로세스는 실제 서버 노드에서 실행되면서도, 마스터 노드에서 프로세스 정보를 관리할 수 있도록 한다. 또한 다른 노드로 마이그레이션이 가능하다. 이를 처리하기 위해 마스터 노드에서 bpmaster 데몬이 동작하며, 실제 서버 노드에서 bpslave 데몬이 동작한다.
1) Scyld의 설치 Scyld는 CD의 형태로 판매된다. http://www.linuxcentral.com에서 주문할 수 있다. ftp를 통해서 받을 수도 있는데, http://www.scyld.com/page/products/beowulf/download.html에서 RPM과 SRPM 패키지들에 대한 링크를 찾을 수 있다. README 파일을 보면 Scyld에 들어있는 패키지들 중에서 어떤 패키지들에 대해 수정이 이루어졌으며, 어떤 패키지들이 추가되었는지를 볼 수 있다. 추가된 패키지들은 bproc, beoboot, beompi, beosetup, beostatus, beowulf-doc, perf, netdiag, mpi-mandel, mpprun, tachyon, libbeostat, npr 등이다. 그리고 고성능 계산을 위한 패키지로서 scalapack, parpack, mpiblacs, atlas, hpl, octave, NAMD 등의 패키지를 포함하고 있다. Scyld의 설치를 위해서는 CD 형태의 패키지를 구입하여 시스템에 처음부터 설치하거나, 레드햇 6.2 호환의 리눅스 운영체제를 설치한 다음, RPM 파일들을 다운로드하여 설치하면 된다.
5. 맺음말 로드밸런싱은 높은 가격대 성능비를 얻기 위한 다양한 클러스터 시스템 설정에서 실제로 높은 성능을 얻기 위해 매우 중요한 부분이다. 행렬의 분할에 의한 계산과 같은 정형화된 문제에 대해서는 굳이 로드밸런싱을 고려하지 않고도 문제를 해결할 수 있지만, 수많은 사용자에게 웹 서비스나 메일 서비스를 제공하기 위한 대규모 서버의 경우에는 2장에서 설명한 로드밸런싱 기법을 사용하면 여러 서버에 부하를 분배시켜서 높은 성능을 얻을 수 있다. 이와 같은 클러스터 설정에서 서버의 수가 늘어남에 따라서 일부 서버에서 에러가 발생할 확률이 증가하는데, 일부 서버의 에러에도 불구하고 전체적인 시스템의 서비스를 계속 제공하기 위해서 3장에서는 고가용성 설정에 대해 설명하였다. 그리고 4장에서는 2장과 같이 각 프로세스가 짧은 시간동안 실행되는 것이 아니라 상당히 긴 시간 동안 실행되는 경우, 특정 노드에 프로세스가 몰려서 성능을 향상시키지 못하는 것을 방지하기 위한 프로세스 마이그레이션 기법에 대해 설명하였다. 클러스터라는 말은 여러가지 시스템 구성에 대해 사용되고 있는데, 이 글에서 다룬 내용은 그 중에서, 성능(웹서버) 클러스터, HA 클러스터, 마이그레이션 클러스터 등이다.계산용 클러스터와, 스토리지 클러스터에 대해서는 이 글에서 자세히 다루지 않았다. 여기서 설명한 내용 외에도, 실제 서버가 수십 대 이상일 때, 데이터베이스 서버가 한 대로 충분하지 않은 경우에 데이터베이스 서버를 여러 대 설치하고 그 중의 한 서버에 대해서만 업데이트를 처리하고, 나머지 서버들은 이 서버로부터 데이터베이스를 주기적으로 복사해서 사용하는 등의 설정 등 높은 성능을 얻기 위한 여러가지 기법을 활용할 수 있다. 리눅스원(주)에서는 이 글에서 언급된 로드밸런싱 솔루션, 고가용성 솔루션, 오라클의 OPS 등을 비롯한 많은 솔루션들을 실제 고객 사이트에서 구축하고 있으며, 이 글에서 언급하지 않은 계산용 클러스터, 저장장치 클러스터 등에 대해서도 연구, 개발, 판매하고 있다. 이들 솔루션에 대한 기술 지원에 대해서는 회사로 연락해 주시길 부탁드린다. (연락처: 02) 3488-9800)
필자: 심마로 연락처 : maro@linuxone.co.kr 리눅스원(주) 연구원, 서울대학교 컴퓨터공학부 박사과정. 관심 분야 : 데이타베이스, 병렬처리, 운영체제, 컴퓨터 구조 등. 현재 생물정보공학(bioinformatics)을 위한 클러스터 기술 연구 개발 중. |








 SteelEye사의 홈페이지는 http://www.steeleye.com이다. 리눅스, 유닉스, 윈도우 NT 등의 OS에서 동작하는 LifeKeeper 솔루션을 공급하고 있다. LifeKeeper 솔루션은 AT&T에 합병되었다가 다시 분리된 NCR에서 파생된 솔루션으로서, 고가용성(High Availability. 99.9%의 가용성, 1년에 8.8시간 미만의 다운 타임)를 넘어서 Fault Resilience (99.99%의 가용성, 1년에 53분 미만의 다운 타임)을 보장한다고 말한다.
SteelEye사의 홈페이지는 http://www.steeleye.com이다. 리눅스, 유닉스, 윈도우 NT 등의 OS에서 동작하는 LifeKeeper 솔루션을 공급하고 있다. LifeKeeper 솔루션은 AT&T에 합병되었다가 다시 분리된 NCR에서 파생된 솔루션으로서, 고가용성(High Availability. 99.9%의 가용성, 1년에 8.8시간 미만의 다운 타임)를 넘어서 Fault Resilience (99.99%의 가용성, 1년에 53분 미만의 다운 타임)을 보장한다고 말한다.

이 글에는 트랙백을 보낼 수 없습니다

by웅쓰
웅자의 상상플러스
|
상상플러스 - 최근 공지
-
pelly.ryu 2016
라고 적고 보니 4번이 눈에 띄었네요. 지우려고 ... -
pelly.ryu 2016
저처럼 누군가 또 찾아올 것 같아 남깁니다.. `$c... -
와우 2014
깔끔하게 풀어두셔서 많은 도움이 되었습니다 ^^ ... -
ghewffsef 2014
잘배우고 갑니다.. 말한마디 한마디 가슴에 와... -
지나가던길 2014
고맙습니다. 많은 참고가 되었습니다.
Copyright ⓒ 2010. 웅쓰, Skin designed by Creasmworks. All rights reserved.
0