 블로그 > 나라사랑하세 블로그 > 나라사랑하세 http://blog.naver.com/cain2332/40009924489 http://blog.naver.com/cain2332/40009924489 | ||
[ Home | Freetime works | FreeBSD | KFUG ] 프로그램세계 2002년 8월분웹 캐시 서버 도전하기최준호, Korea FreeBSD Users Group <cjh at kr.FreeBSD.org>이번달에는 가장 많이 사용하는 인터넷의 도구인 웹에 관련된 캐시 서버에 대해서 알아 보자. 일반적으로 웹 서버에 대한 설정이나 관련 내용은 많지만 상대적으로 캐시에 관련된 내용은 적은 편이다. 웹 캐시는 이용도에 따라 다양한 활용이 가능하므로 꼭 한번 살펴보기 바란다.
FreeBSD와 웹 캐시웹 캐시란?인터넷상의 대부분의 트래픽을 차지하는 HTTP 프로토콜은 주로 웹 페이지 또는 파일이라는 객체 단위의 전송을 지원하는 프로토콜이라 생각하면 되며, 접근할 수 있는 각 객체에는 URL이라는 유일한 이름이 붙어 있다(여기에 쿠키나 CGI 인수 등이 추가되기도 한다). 일반적으로는 사용자의 웹 브라우저에서 웹 서버까지 직접 접속하여 URL로 지정된 웹 객체를 전송해 와서 적절한 MIME 타입에 따라 사용자 화면에 표시하는 구조로 되어 있다. 사람들이 많이 몰리는 웹 사이트의 경우 접속이 빈번해지면 웹 서버는 부하를 많이 받게 된다. 웹 서버의 부하를 낮추는 방법에는 여러가지가 있지만, 가장 편리한 방법 중의 하나는 사용자의 웹 브라우저와 웹 서버 사이에 웹 캐시를 중간에 두어 지나가는 내용을 캐싱하도록 하는 것이다. 웹 캐시는 HTTP 프로토콜의 서버와 클라이언트 양방향으로 동작하여 웹 브라우저 입장에서는 웹 서버로, 웹 서버 입장에서는 웹 클라이언트의 형태로 동작하며, 브라우저와 서버 사이의 URL 객체를 조건에 따라 캐시의 저장 공간에 저장하고 이용자의 요청이 웹 서버에게 불필요한 경우 캐시가 직접 처리하도록 되어 있다. 하지만 캐시라는 것은 여러 수준에서 존재할 수 있다. 웹에 관련된 것이라면, 일차적으로 웹 브라우저가 있는 PC에서 메모리와 디스크에 각 객체를 캐싱하고(인터넷 익스플로러나 넷스케이프 네비게이터, 모질라의 경우 각각 메모리와 디스크 캐시에 대한 설정을 찾아볼 수 있다) 있으므로 직접 연결시에도 전혀 캐시가 적용되지 않는 것은 아니다. 웹 캐시의 종류웹 캐시에는 크게 두가지의 용법이 있다.
결국 캐시라는 것은 사용자 - 웹 서버 간의 구간 어디엔가에 놓여서 트래픽을 줄이기 위한 목적으로 사용되는 것이지만, HTTP 프로토콜 자체가 모두 캐시를 통해 지나가는 특성상 이를 응용하여 여러가지 일이 가능하다. 예를 들면 다음과 같다.
캐시 관련 포트웹 캐시에 관련된 포트는 대부분 www 카테고리에 존재한다. 대부분의 포트는 웹 캐시 또는 캐시에 관련된 유틸리티(통계, 캐시 브라우저 등)이다. squid (www/squid)오픈 소스로 된 웹 캐시 중 가장 유명한 것은 squid(www/squid)이다. squid는 원래 Harvest라는 프로젝트의 일부였으나 Harvest 프로젝트가 종료된 뒤에 웹 캐시 부분이 따로 계속 발전하여 현재의 형태에 이르고 있다. squid는 웹 캐시에 필요한 모든 기능을 제공하고 있는 완전한 웹 캐시 소프트웨어이다. 상용 웹 캐시에 비해 성능이 조금 떨어질지는 모르겠지만, 실제 중소규모의 네트워크에서 사용하기에는 조금도 부족함이 없는 수준이다. squid 프로젝트의 홈페이지는 아래 주소이다. Squid Web Proxy Cache: http://www.squid-cache.org현재의 안정 버전은 2.4이이다. 이 글에서는 2.4 버전을 간단히 설정하고 사용하는 방법에 대해 알아 보자. 이 글에서는 주로 프록시 캐시의 사용법에 대해서 알아보겠다. 리버스 캐시의 경우 L4 스위치 등과 같이 이용해야 하는 경우가 많으므로 이 부분에 대해서는 독자에게 맡기겠다. squid의 설치와 설정: 프록시 캐시squid의 설치에 대해서는 별다르게 말할 것이 없다. 기본적으로는 패키지를 설치하거나 www/squid24 포트에서 설치하면 되는데, 포트 설치시 많은 옵션을 줄 수 있으므로 www/squid24/Makefile을 꼭 보기 바란다. 기본적인 캐시 설정을 위해서는 추가로 해 주어야 할 것은 없으므로 잘 모르면 그대로 설치하기 바란다. 설치 후를 보면 대몬의 시작/정지 스크립트는 /usr/local/etc/rc.d/squid.sh 에 설치되어 있다는 것을 알 수 있다. 실제로는 RunCache라는 명령을 부르게 되며, RunCache는 다시 squid라는 프로그램을 대몬 형태로 실행시킨다. 설정 파일은 /usr/local/etc/squid/squid.conf를 설정하면 된다. 이 파일은 매우 크기가 크고 다양한 설정이 가능한데, 여기서는 최소한의 설정에 대해서 알아 보자. 나머지는 squid의 문서 등을 참고해서 스스로 해 보기 바란다. # 캐시 서버의 포트를 지정한다. 보통 프록시 캐시로 쓰는 경우는# 3128번이고, 리버스 캐시로 사용한다면 80번으로 쓰는 경우가 많다.http_port 3128# 캐시용 메모리 크기를 지정한다.cache_mem 8 MB# 캐싱할 수 있는 최대 객체 크기를 정한다.maximum_object_size 4096 KB# 캐시 보관용의 디스크 영역을 지정한다.# 첫번째 인수인 ufs는 디스크 관리 방법(가장 보통인 것)을 나타내며,# aufs, diskd 등의 대체 키워드를 사용할 수 있다.# 두번째 인수는 캐시의 디렉토리이다. 용량이 충분한 디렉토리를# 지정한다.# 세번째 인수는 캐시의 최대 크기를 M바이트 단위로 지정한다.# 1500의 경우 1500M(1.5G) 를 나타낸다.# 네번째 인수와 다섯번째 인수는 캐시 디렉토리의 갯수를 나타내는데,# 캐시 디렉토리 아래 네번째 인수만큼의 디렉토리를 만들고, 그 아래# 다섯번째 인수만큼의 디렉토리를 만든다. 이를 통해 빠르게 캐시# 객체를 찾아갈 수 있다.cache_dir ufs /spool/cache/spool 1500 16 256# 캐시의 접근 로그를 저장한다. webalizer같은 로그 분석 도구로# 분석할 수 있다.cache_access_log /spool/cache/logs/access.log# 캐시에 대한 행동 로그 파일을 지정한다.cache_log none# 캐시 저장에 관련된 로그를 기록한다. 보통은 필요 없다.cache_store_log none# squid는 FTP 캐시도 가능한데, 이 경우 사용자 대신 실제 FTP 서버에# 익명 로그인할 경우의 id를 지정한다. 웹 캐시는 FTP 접속을 대신하는# 경우, 알맞은 인덱스 파일을 생성해 준다.ftp_user Squid@# 접근 제어 목록을 지정한다. 캐시에 아무나 접근할 수 있다면 불필요한# 외부 접속과 트래픽을 발생할 수 있다.# acl 다음은 그룹 이름, 그 다음에 포트, IP 주소 등을 지정할 수 있다.acl all src 0.0.0.0/0.0.0.0acl manager proto cache_objectacl localhost src 127.0.0.1/255.255.255.255acl SSL_ports port 443 563acl Safe_ports port 80 # httpacl Safe_ports port 21 # ftpacl Safe_ports port 443 563 # https, snews# http_access 뒤에는 allow/deny의 동작을 지정하고 acl 에서 지정했던# 그룹을 지정한다.# 아래의 경우 manager 그룹과 localhost 그룹은 접근을 허가,# 다음 행에 의해 localhost 이외의 manager 그룹은 접근이 안되는 것을# 알 수 있다.http_access allow manager localhosthttp_access deny manager# Safe_ports 이외는 거부(!은 not의 의미를 갖는다)http_access deny !Safe_ports# SSL_ports(443, 563 포트)가 아니면 CONNECT 그룹을 허가하지 않는다.# CONNECT 그룹은 acl에서 CONNECT 메소드를 나타낸다.http_access deny CONNECT !SSL_ports# 아래 예는 자신의 네트워크를 정의하고 여기에 대해 접속을 허가하는# 경우이다. 자신의 네트워크는 여기서 192.168.1.0/24 이다.acl myhome src 192.168.1.0/255.255.255.0http_access allow myhome# 가장 끝에는 명시적으로 allow all이나 deny all을 적어주기 바란다.# 아래와 같이 적어주면 위의 allow 규칙에 해당되지 못한 요청은 이 줄에# 의해서 모두 거부된다.http_accessde deny all 대략 설정이 끝났으면 squid를 실행해 보자. 실행하기 전에 해야 할 일은 먼저 캐시 디렉토리를 만드는 일이다. 위에서 cache_dir 에서 지정한 디렉토리를 만들고, squid -z 를 이용해서 캐시 디렉토리 아래의 하부 디렉토리를 생성한다. # mkdir -p /spool/cache/spool# chown -R nobody:nogroup /spool/cache/spool# squid -z 잠시 후에 디렉토리 생성이 종료될 것이다. squid는 nobody 권한으로 실행되기 때문에 (cache_effective_user, cache_effective_group 으로 설정한다) 해당 사용자가 읽고 쓰기 가능하도록 권한을 변경해 주어야 한다. /tmp 처럼 sticky 비트를 지정하는 것도 좋은 생각일 것이다. 다 되었다면 이제 캐시를 실행해 보자. # /usr/local/etc/rc.d/squid.sh start 실행이 잘 되고 있는지는 사용자의 웹 브라우저에서 프록시를 해당 IP와 포트(기본인 경우 3128)번으로 설정하고, 다시 브라우저를 실행한 후 웹 브라우징이 잘 되는지 확인해 보면 된다. IE의 경우, "도구" - "인터넷 옵션" 탭을 선택한 후 "연결" 탭, "LAN 설정(L)..." 을 선택하면 프록시 입력 화면으로 이동할 수 있다. 여기서 "프록시 서버 사용"을 선택하고 서버 IP와 포트 이름을 적어주면 된다. 넷스케이프라면 "편집" - "설정" 메뉴의 "고급" - "프락시" - "프락시 수동 설정" 탭을 이용하면 된다.
그러면 이후의 HTTP 접속은(FTP나 Gopher도 프록시 캐시를 이용할 수 있다) 모두 지금 설정한 캐시를 통하게 된다. 정상적으로 웹 브라우징이 되는 경우라면 잘 되는지의 여부를 확인할 수 있다. 만약 이 방법으로 연결이 잘 안되거나, proxy가 어떤 오류 메시지를 내보낸다면(squid가 아예 제대로 떠 있지 않은 경우를 제외한다면 오류 메시지는 브라우저에 표시된다) 이를 보고 적절히 대처해 주면 된다. 대부분이 경우 squid.conf의 설정 변경으로 해결할 수 있다. 다음 사이트를 사용하면 캐시의 사용 여부와 캐시가 외부에서 이용 가능한지를 점검할 수 있다. 만약 외부에서 접근이 가능하다고 나오는 경우 일부러 열어둔 것이 아니라면 squid.conf의 acl 부분을 다시 보고 한정된 범위만 프록시 연결을 허가하기 바란다. 가장 아래쪽의 "Environment Variable Check"를 선택하고 "Show Proxy related Variable"을 선택하면 HTTP_VIA 헤더에 현재 사용하고 있는 캐시의 IP와 포트 번호가 나온다. 만약 자신이 사용하고 있지 않은 프록시가 출력되는 경우 대부분 ISP에서 직접 설치해 놓은 캐시인지 의심해 볼 필요가 있다. 대형 ISP의 경우 HTTP 접속을 줄이기 위해 라우터 수준에서 투명 프록시를 설치해 둔 경우가 많다. Proxy Checker: http://cache.jp.apan.net/proxy-checker/FreeBSD에서는 HTTP_PROXY와 FTP_PROXY 환경 변수를 사용해서 fetch, lynx 등의 명령이 프록시를 거치도록 할 수 있다. 방화벽 내에 있는 환경이라든가 프록시를 써야 하는 환경이라면 포트 등의 설치에서 이 변수를 지정하도록 할 수 있다. ports의 경우 많이 쓴다면 make.conf 에서 지정해 두자. FETCH_ENV= HTTP_PROXY=http://192.168.1.1:3128 squid의 관리squid는 -k 옵션을 통해 여러가지 관리 명령을 실행할 수 있으므로 대몬 관리에 조금 도움이 될 것이다. squid -k reconfigure|rotate|shutdown|interrupt|kill|debug|check|parse 특히 reconfigure, shutdown, kill 등은 웹 캐시 프로세스를 빠르게 제어할 수 있다. 설정이 변경된 경우 reconfigure를, 서버를 중지시키고 싶은 경우 shutdown이나 kill(kill이 더 강제적이다)을 사용하기 바란다. squid의 경우 프로세스가 비정상적으로 종료되어도 다시 시작하기 때문에 프로세스를 직접 kill로 정지시키는 일이 잘 안되는 경우가 많다. # squid -k reconfigure squid의 설치와 설정: 투명 캐시프록시 캐시는 설치가 간단하고 이용이 비교적 쉽다는 점이 있지만, 대상이 되는 네트워크에 많은 수의 클라이언트 PC가 있다면 일일이 환경 설정을 열어서 프록시 캐시를 지정해 주기는 어려운 점이 많다. 이러한 경우 방화벽을 사용하고 있다면 투명 캐시라는 기능을 사용하면 사이트 전체의 전역 설정으로 바꿀 수 있다. 투명 캐시는 웹 서버로 가는 패킷의 흐름을 강제적으로 캐시로 돌려주고, 캐시가 대신 웹 서버에 접속하도록 한다. 이번 경우는 다음 네트워크를 예로 들도록 하자. 지금은 ipfw를 사용하는 예를 들지만, 대부분의 패킷 필터 방화벽은 비슷한 설정을 제공한다. 점검이 끝났으면 squid를 다시 시작해 두자. 그 다음은 방화벽인데, 보통은 NAT를 사용하는 경우 다음과 같이 방화벽이 설정되어 있을 것이다. 조금 다른 주제로 오프라인 캐시에 대해서 다루어 보자. 최근의 브라우저는 오프라인 기능이 있어서 인터넷 접속이 안되는 경우에도 이미 캐시에 존재하는 페이지만으로 브라우징이 가능한 기능을 제공하지만, 이를 캐시 수준에서 할 수 있지 않을까? 하는 생각으로 만들어진 것이 wwwoffle 등의 오프라인 캐시이다. 이러한 캐시는 프록시 캐시의 형태로 동작하며, 최대한 캐싱하고 있다가 원래 사이트에 접근이 안되는 경우에도 사용자가 잘 모를 정도로 캐싱하고 있는 데이터를 전송해 준다. 이러한 캐시는 모뎀 등의 저속 환경 사용자, 빈번이 끊어지는 네트워크 환경을 이용하고 있는 사용자에게 매우 유용하다. 가정에서 인터넷 환경을 사용하는 경우라면 조금 무거운 squid보다는 이러한 캐시가 더 유용할 지도 모른다. 대신 wwwoffle는 리버스 캐시 등의 다양한 기능은 이용할 수 없다. wwwoffle는 www/wwwoffle 포트를 설치하면 된다. 설치 후에는 설정 파일을 만들기 위해 다음과 같이 템플릿에서 한부 복사해 오면 된다. wwwoffle.conf의 설정은 squid보다 더 친절하게 설명되어 있는 관계로 쉽게 설정할 수 있을 것이다. 가장 기본적인 것은 StartUp 부분이다. wwwoffle 대몬을 실행한 후(/usr/local/etc/rc.d/wwwoffle.sh), 이 대몬의 제어는 squid -k와 비슷하게 wwwoffle 프로그램을 사용하면 된다. squid에 없는 재미있는 설정은 온/오프라인 설정이다. 프록시 서버를 온라인 모드로 한다. 모든 웹사이트에 직접 접근 가능한 경우이다. 모뎀이나 ISDN 등의 사용자의 경우 필요하면 외부에 접속하지만 네트워크 연결 없이 캐시에서 바로 돌려줄 수 있다면 그렇게 한다. 외부와 접속이 끊어진 경우, 오프라인 모드로 동작한다. -online이나 -offline의 경우 모뎀 등의 ppp의 시동/종료 스크립트에 넣어두면 편리하다. 현재 캐싱된 요청을 모두 다시 읽어들인다. 그외 설정을 다시 읽으려면 -config, 캐시를 비우려면 -purge, 대몬을 정지시키려면 -kill 옵션을 사용한다. 아마 이정도로도 충분히 재미있게 사용할 수 있을 것이다. 또한 특정 URL을 지정하여 읽어들여 두는 옵션도 가능하다(-O URL). 그외 wwwoffle은 목적에 따라 HTML을 그대로가 아니라 약간 변형하여 캐시에 저장할 수 있는(animated gif를 정지 이미지로 바꾸거나 스크립트 실행을 금지시키는 등) 기능을 제공하므로 설정 파일을 읽어보고 따라해 보도록 하자. 단 이러한 대몬의 단점은 캐싱 기능에 초점을 맞춘 것이므로 조금은 오래된 데이터를 바로 돌려줄 수 있다는 것이 단점이다. 브라우저의 다시 읽기 단추를 사용하거나 항상 online 모드로 두도록 하자. 그 외 캐시 서버로 동작하는 것은 광고 제거 서버인 www/junkbuster, www/adzapper 등을 들 수 있다. 이러한 프록시는 웹 페이지 내의 광고 이미지를 빈 이미지로 돌려 주거나 아예 돌려주지 않는다. 이렇게 하면 광고가 많은 사이트의 접속을 빠르게 할 수 있다. dansguardian (www/dansguardian) 도 비슷한 역할을 할 수 있지만 이는 squid와 같이 사용한다. 이외 oops, tinyproxy 등 프록시 역할을 할 수 있는 다양한 프로그램들이 있다. 이번 기사에서 다루지 않은 내용 중 더 배워 볼 만한 주제는 다음과 같다. 이후에 웹 캐시 서버를 관리하게 된다면 꼭 한번씩 해 보자. 이번 기사에서는 웹 캐시의 다양한 활용 방법에 대해 알아보았는데, 집이나 사무실이라면 광고 제거 서버 등은 한번 사용해 보면 편할 것이다. 물론 윈도 등에 설치하는 광고 제거용 프록시(이것도 결국 프록시 캐시로 동작하는 프로그램이다)들도 많이 있지만, 사이트 전체에 적용해 보는 것도 재미있을 것이다. | ||



| 블로그 > seafig님의 블로그 http://blog.naver.com/seafig/60005184191 | |
| 아파치에서 전송 속도 제한하기 (모든 설명은 레드햇 6.0을 기준으로 합니다.) 1. 아파치 1.3.x용 bandwidth 모듈이 필요합니다. ftp://ftp.cohprog.com/pub/apache/module/1.3.0/mod_bandwidth.c를 받아 오시면 됩니다. 레드햇 6.0 이상을 기반으로 한 배포판에는 이 모듈이 포함되어 있습니다. /usr/lib/apache/mod_bandwidth.so가 이미 존제하는 분은 컴파일 과정을 생략하시면 됩니다. 참고: 레드햇에 포함된 버젼은 1.2 버젼입니다. 최신 버젼은 2.0 버젼이며 다음의 설명들에 1.2 버젼에는 없는 기능의 경우에는 *로 마크를 하겠습니다. 2. 아파치 모듈로의 컴파일이 필요합니다. o 아파치 소스와 같이 컴파일 하려면 아파치 소스의 src/modules/extra/ 디렉토리로 mod_bandwidth.c를 복사한 후에 ./configure시에 --add-module=mod_bandwidth.c 옵션을 주시면 됩니다. o 직접 컴파일 하려면 다음의 명령을 따라하시면 됩니다. 물론 그러기 위해서는 아파치의 개발용 헤더들이 시스템에 설치되어 있어야 합니다. 레드햇의 경우 apache-devel이라는 패키지로 존재합니다. 그 위치는 /usr/include/apache/에 있습니다. (배포판에 따라 틀릴 수 있습니다.) $ gcc -c -I/usr/include/apache -O2 -m486 -fno-strength-reduce mod_bandwidth.c -fpic -DSHARED_MODULE mod_bandwidth.c $ gcc -shared -o mod_bandwidth.so mod_bandwidth.o $는 쉘 프롬프트를 나타내며 는 줄이 이어진다는 뜻입니다. 그러니까 한 줄로 붙여 쓰시기 바랍니다. 3. 컴파일된 모듈을 아파치 모듈이 위치하는 디렉토리로 옮기시기 바랍니다. 레드햇의 경우 /usr/lib/apache/에 위치합니다. 직접 컴파일하셨다면 지정한 것에 따라 틀릴 수 있습니다. 알아서 하시기 바랍니다. :) 4. 아파치의 설정 파일을 고쳐야 할 것입니다. 그럼 하나씩 고치는 방법에 대해서 알아 보겠습니다. 1. 모듈로 컴파일 했기 때문에 모듈을 읽도록 해야 합니다. httpd.conf에서 LoadModule foobar_modules modules/mod_foobar.so 같은 내용이 있는 부분이 있습니다. 그 하단부에 다음 줄을 추가 하십시오. LoadModule bandwidth_module modules/mod_bandwidth.so 마지막은 모듈의 위치입니다. 설치한 것에 따라 설정하십시오. httpd.conf 설정에 ClearModuleList가 있다면 다음 줄이 추가되어야 합니다. AddModule mod_bandwidth.c 비슷한 내용이 있는 부분의 아래에 적으시면 될 것입니다. :) 2. 이제 전송 속도 제한 기능을 하는 모듈을 사용하겠다는 것을 지정해 주어야 합니다. 디렉토리별 설정 위에 다음 줄을 추가하시면 됩니다. BandWidthModule On 3. 이 모듈이 사용하기 위해서는 데이타를 기록할 장소가 필요합니다. 기본값으로 /tmp/apachebw 디렉토리를 사용합니다. /tmp/apachebw/link /tmp/apachebw/master 이렇게 디렉토리를 생성해 주시십시오. 퍼미션은 nobody 사용자가 쓸 수 있는 권한이 있어야 합니다. (여기서 nobody는 아파치가 사용하는 사용자입니다. 다른 사용자를 사용한다면 그 사용자의 권한으로 줘야 겠지요.) 생각하기 싫으신 분은 다음 명령을 실행하십시오. chown root.nobody /tmp/apachebw chmod -R 770 /tmp/apachebw/ 4. 이제 실제적인 전송 속도 제한의 옵션을 알아 보겠습니다. BandWidth, LargeFileLimit, MinBandWidth 이렇게 세가지의 지시자?가 있습니다. 각각에 대해서 알아 봅시다. o BandWidth 문 법: BandWidth <도메인|IP주소|all> <속도> 기본값: 없음 사용처: 전체 설정, 디렉토리별 설정, .htaccess 호스트에 따라 속도의 제한을 걸 수 있습니다. all은 모든 호스트에 대해서 제한을 거는 것입니다. 도메인이나 IP주소로 접속 호스트를 지정할 수 있습니다. 그리고 네트워크/마스크 포맷*으로 지정할 수도 있습니다. (예: 192.168.0.0/24) 속도는 Bytes/second로 나타냅니다. 0의 경우는 제한이 없는 것입니다. 디렉토리별 설정에서 사용한 예를 들겠습니다. BandWidth 192.168.1 0 BandWidth foobar.net 0 BandWidth all 1024 /home/httpd/html 디렉토리에서의 제한을 한 것입니다. 192.168.1.* IP 주소를 가진 호스트와 *.foobar.net이라는 도메인명을 사용하는 호스트에 대해서는 제한을 걸지 않으며 그 외 모든 접속에 대해서 1024Bytes/sec으로 제한을 걸었습니다. o LargeFileLimit 문 법: LargeFileLimit <파일크기> <속도> 기본값: 없음 사용처: 전체 설정, 디렉토리별 설정, .htaccess 일정 이상의 크기를 가진 파일을 누군가가 받아 가려 할 때 그 속도의 제한을 걸 수 있습니다. 파일크기는 KByte 기준이며 속도는 역시 Bytes/secound입니다. LargeFileLimit 1024 4096 LargeFileLimit 2048 2048 위 예제는 1024 ~ 2047KB 크기의 파일을 받아가려 할 때 속도를 4KB/sec으로 제한하고 2048KB 이상의 파일은 2KB/sec으로 제한을 하는 것입니다. o MinBandWidth 문 법: MinBandWidth <도메인|IP주소|all> <속도> 기본값: all, 256 사용처: 전체 설정, 디렉토리별 설정, .htaccess 데이타 전송의 최저 속도를 지정하게 됩니다. 예를 들어서 설명하는 것이 가장 좋을 것 같군요. BandWidth를 4096 (4KBytes/sec)으로 지정하고 MinBandWidth가 1024로 지정이 되어 있을 때: - 지정된 호스트에서 하나만 접속할 경우, 4096bytes/sec이 최고의 속도가 됩니다. - 지정된 호스트에서 두개가 동시에 접속할 경우, 각각의 세션에 대해 2048Bytes/sec이 최고의 속도가 됩니다. - 더 많은 동시 접속이 일어나도 세션 당 최고 속도는 1024Bytes/sec 이하로는 줄지 않습니다. (MinBandWidth 값이 1024기 때문에) MinBandWidth가 "-1"로 지정되면 모든 세션에 대해 최고 속도는 BandWidth나 LageFileLimit에서 지정한 속도가 나올 수 있게 됩니다. BandWidth를 4096으로 지정하고 MinBandWidth가 -1이라면 동시에 지정된 호스트에서 몇개의 접속을 하더라도 각 세션의 속도는 4096Bytes/sec 까지 나오게 되는 것입니다. 출처: 적수네 |

| 블로그 > 헤즐넛 - 더욱 강렬하게 http://blog.naver.com/designfull/120000669782 | |||||||||||||||||||||||||||||||
자료출처 : http://ngps.net/ngpiki/index.php?display=MySqlForCApi 간단하게나마 DB에서 가장 많이 사용되는 ( 게임용 DB 로도 가장 많이 사용 되는 ) MySQL For C API 에 대해서 알아 보고 최후로 DB 접근을 하기 위한 종단 서버 구성으로 마쳐 볼까 합니다 :) 이것 역시 언제 끝날지는 알 수 없습니다 시간 날 때마다 하겠습니다. 개인적으로 sql query문이 제가 약한 관계로 :) 제대로 된 글이 될 거라는 생각은 안 합니다. 휴 정말 간만에 들어오네요 :) 제가 너무 정신이 없어서 ( 논다고 바빳습니다. 기다리는 분은 전혀 없었겠지만 ) 2번에 나놔서 정리 할까 합니다. 첫번째로는 함수 나열과 정리를 하고 두번째는 실전 소스로 나눠서 정리할까 합니다. 실제 많은 api함수들이 있지만 자주 사용하는 것 몇가지만 알아보겠습니다. 아.. VS6에서는 컴파일을 위해서는 MYSQL/INCLUDE 폴더를 포함시켜 주시고 libmysql.lib를 포함 시키지 않으면 반가운 링크에러들이 뜰겁니다. 리눅스에서는 make 파일에 여러가지를 추가 시켜야겠죠. 정확한 include 파일 경로를 찾으려면, # find / -name mysql.h 정확한 공유 라이브러리 파일 경로를 찾으려면, # find / -name libmysqlclient.so 하시면 됩니다.
와 같이 하면 컴파일에 문제가 없을겁니다. 컴파일 얘기는 다음에 한번더 자세하게 makefile과 함께 하고 오늘은 자주 사용하는 함수만 정리 하겠습니다.
이제는 저 위에 함수들을 어떻게 사용 하는가에 대해서 간단한 예문을 통해서 알아 볼까 합니다. 지금 위키에서 바로 코딩을 하는 관계로 컴파일이 안됄수도 있습니다 (__) 그냥 어떻게 사용하는가만 알아 보자는 겁니다. 쿨럭;; #define dDB_HOST "아이피"#define dDB_PORT 3306#define dDB_ID "아이디"#define dDB_PW "db 패스워드"#define dDB_NAME "DB 명 "#include <mysql.h>MYSQL* mysql;MYSQL *DBConnect( char * host , int port , char *id , char *pw , char *dbName ){ MYSQL *db = NULL; db = mysql_init( (MYSQL*)NULL ); // 초기화 함수 if( db ) { if( mysql_real_connect( db, host, id, pw, NULL, port, (char*)NULL, 0 ) ) // DB 접속 { if( mysql_select_db( db, dbName ) != 0 ) // DB 선택 { mysql_close( db ); return NULL; } } else // connect error { printf( "Error %d ( %s )\n", mysql_errno( db ), mysql_error( db ) ); mysql_close( db ); return NULL; } } else return NULL; return db;}int main(){ mysql = DBConnect( dDB_HOST , dDB_PORT, dDB_ID , dDB_PW, dDB_DBNAME ); if( ! mysql ) { return -1 ; } char Query[128]; sprintf( Query," select ......등등 필요한 쿼리들" ); if( !mysql_query ( mysql, Query) ) { MYSQL_RES *result = mysql_store_result( mysql ); if( result ) { MYSQL_ROW row; row = mysql_fetch_row( result ); // 그리고 각 원하는 것들을 여기에다가 변수에 저장 한다. // id = atoi ( row[0] ) ; 이런 식으로 ... } mysql_free_result( result ); } mysql_close( mysql ); return 0;}정말 간만에 수정 하는 군요 -_-+ 몇마디 더 추가 하고자 이렇게 글을 올리게 됐네요
이런식으로적으면 컴파일이 돼겠습니다요 이렇게 하면 mysql 이라는 게 생기겠죠 뭐 더 확실하게 알아 보고자 하면 연결 완료 나 종료에 대해서 printf 문등을 통해서 알아보던지 아니면 로그파일로 남기셔도 될듯하고요 여기서 주의 할점은 Mysql For C API를 사용할때는 -lmysqlclient 이 녀석입니다. 라이브러리를 연결 하는 녀석이죠 libmysqlclient.so 를 찾아서 링크 시켜 주는 역할을 합니다. 자 여기서 C API 의 자료형에 대해서 몇가지 알아 보겠습니다.
(에러 문구는 mysql for C API 문서에서 발견을 했는데 출처를 모르겠군요 ) 이번에는 Mysql For C API 를 이용하면서 나올 에러들에 대해서 대처해보기 위해서 에러에 대해서 알아 보겠습니다. 1) "msyql.c:2: mysql.h: 그런 파일이나 디렉토리가 없음"
2) "mysql.o(.text+0x11): undefined reference to `mysql_init'"
3) "ld: cannot open -lmysqlclient: 그런 파일이나 디렉토리가 없음"
4) "Can't connect to local MySQL server " 5) "Access denied for user: 'root@localhost' (Using password: YES)"
6) "./sql: error in loading shared libraries libmysqlclient.so.6: cannot open shared object file: No such file or directory" | |||||||||||||||||||||||||||||||
| 블로그 > Do it Now http://blog.naver.com/idxzone/60000551074 | |
Didn't find any fields in table 'XN__free' mysql> desc XN__free ; [10:24:12 /usr/local/mysql/data/g_gaya]# /usr/local/mysql/bin/myisamchk XN__free.* [10:25:57 /usr/local/mysql/data/g_gaya]# /usr/local/mysql/bin/myisamchk XN__qna.* ++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++ 복구방법 myisamchk 라는 것이 있다. # myisamchk -r TEST.MYI
++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++ 에러 메세지 : --
#복구 #안전하게 복구 #데이터 정렬 및 속도 증가 -R1 저도 주면 될듯 싶네요
35 0 * * 0 /path/to/myisamchk -s /path/to/datadir/*/*.MYI This prints out information about crashed tables so we can examine and repair them when needed.
myisamchk , 디비 복구에 관련된 url 들 http://www.mysql.com/doc/en/myisamchk_repair_options.html
http://database.sarang.net/database/mysql/doc/mysql-3.23.32/manual-split/manual_Maintenance.html
http://www.mysql.com/doc/en/Repair.html
http://linuxpro.pe.kr/document.files/man/mysql_3.23.28/manual_Table_types.html |
| 카페 > 하준용 in Net / likeasky님 http://cafe.naver.com/likeasky/78 | |
http://www.phpschool.com/bbs/view.html?id=2590&code=tnt&start=0 http://tunelinux.pe.kr/bbs/read.php?table=linuxinfo&no=18&o[at]=s&o[sc]=t&o[ss]=mrtg&o[st]=a http://www.wowlinux.co.kr/download/specialview.html?id=55&view=1 http://tunelinux.pe.kr/bbs/read.php?table=linuxinfo&no=72
mrtg설치시 gd가 필요하고 gd는 zlib랑 모가 필요하다는데 요즘 배포판에 모두 설치되어 있는 것들임.. 그냥 ./configure 하면 됨.. snmpd 떠 있으면 ./cfgmaker 가 mrtg.cfg 화일 제대로 만들어줌.. 수작업으로 mrtg.cfg 화일 편집해야함(snmpd.conf도 함께.. 리부팅 필요)
Target[traffic]: 2:public@ns2.myfolder.net: ################################################################################ Target[http]: `/usr/local/mrtg-2.9.10/web_count.sh` ################################################################################ Target[mysql]: `/usr/local/mrtg-2.9.10/mysql_count.sh`
Target[load]: .1.3.6.1.4.1.2021.10.1.3.2&.1.3.6.1.4.1.2021.10.1.3.3:public@localhost * 100 ################################################################################ Target[memory]: .1.3.6.1.4.1.2021.4.6.0&.1.3.6.1.4.1.2021.4.15.0:public@localhost * 1024 ################################################################################
Target[disk2]: .1.3.6.1.4.1.2021.9.1.8.3&.1.3.6.1.4.1.2021.9.1.8.4:public@localhost indexmaker mrtg.cfg > index.html 하면 여러페이지를 하나의 인덱스 페이지로 만들어줌.. 크론에 등록해야 함.. |
| 블로그 > 홍이얌 http://blog.naver.com/meetjava/100006369952 | |
[ myisamchk 란 ? ] - DB 테이블에대한 오류 검사 및 오류 복구 유틸리티 - 버전 3.22.x : isamchk 유틸리티 사용 3.23.x : myisamchk 유틸리티 사용 [ myisamchk 사용전 주의사항 ] - mysql 데몬을 stop 시킨후 이 유틸리티를 사용해야한다. - mysql 데몬을 중지시킬수 없는 사항이라면 검사할 테이블에대한 rock을 걸고 검사를 수행하여야만 검사도중에 발생할수있는 오류를 막을수있다. - 모든작업이 그렇듯이 항상 백업을 한후 작성을 수행하는것이 좋을것이다. [ myisamchk 사용법 및 옵션 ] - 해당 테이블이있는 디렉토리로 이동 ( 일반적으로 /usr/local/mysql/var 밑에 위치함 ) 1.일반적인 검사 [root@angelsoma var]myisamchk [table 명] Checking MYISAM file: [table 명] Data records: 271 Deleted blocks: 0 - check file-size - check delete-chain - check index reference - check record links 에러메시지가 없으면 테이블에 오류가 없다는것이다. 2.Global 옵션 [root@angelsoma var]myisamchk -s,--silent [table 명] 에러만 출력한다. [root@angelsoma var]myisamchk -v,--verbose [table 명] -s 옵션보다 많은 정보를 출력한다. [root@angelsoma var]myisamchk -V myisamchk 버젼을 표시한다. 3.Check 옵션 [root@angelsoma var]myisamchk -c,--check [table 명] 테이블의 에러를 check 한다. [root@angelsoma var]myisamchk -e,--extend-check [table 명] 테이블을 좀더 세밀하게 check 한다. 일반적인 방법으로 error를 찾을수없 경우 사용하는 옵션이다. [root@angelsoma var]myisamchk -F,--fast [table 명] 빠른게 테이블 check 한다.정교한 체크는 하지않느다. [root@angelsoma var]myisamchk -C,--check-only-changed [table 명] 테이블을 check 하고,테이블을 check 이후의 상태로 변경한다. [root@angelsoma var]myisamchk -f,--force [table 명] 테이블에 error에 있을경우 강재로 check 한다. [root@angelsoma var]myisamchk -i,--information [table 명] check한 결과의 정보를 통계화하여 보여준다. Checking MyISAM file: insertdb Data records: 8962 Deleted blocks: 0 - check file-size - check key delete-chain - check record delete-chain - check index reference - check data record references index: 1 Key: 1: Keyblocks used: 97% Packed: 0% Max levels: 2 Total: Keyblocks used: 97% Packed: 0% - check record links Records: 8962 M.recordlength: 241 Packed: 0% Recordspace used: 100% Empty space: 0% Blocks/Record: 1.00 Record blocks: 8962 Delete blocks: 0 Record data: 2166962 Deleted data: 0 Lost space: 6796 Linkdata: 33634 User time 0.21, System time 0.02 Maximum resident set size 0, Integral resident set size 0 Non-physical pagefaults 92, Physical pagefaults 198, Swaps 0 Blocks in 0 out 0, Messages in 0 out 0, Signals 0 Voluntary context switches 0, Involuntary context switches 0 [root@angelsoma var]myisamchk -m,--medium-check [table 명] extend-check 옵션보다 check 속도가빠르며,99.9 % 의 에러을 찾을수있다. 4.Repair 옵션 [root@angelsoma var]myisamchk -o -B,--backup [table 명] - recovering (with sort) MyISAM-table 'insertdb.MYI' Data records: 8962 - Fixing index 1 MYD파일을 백업한다. 형식은 [filename-time.BAK]의 파일이 생긴다. [root@angelsoma var]myisamchk -e,--extend-check [table 명] 세부적인 파일까지 복구를해준다.일반적으로 아주 하찮은 에러까지 찾을수 있다.하지만 자포자기의 상태가 아니고서는 이옵션을 사용하지 않는게 좋다. [root@angelsoma var]myisamchk -f,-force [table 명] 이전것의 temporary file을 덥어쒸운다. [root@angelsoma var]myisamchk -l,--no-symlinks [table 명] 심복릭 링크를 따르지않겠다는 옵션이다. 일반적으로 myisamchk 는symlink points를 복구한다. [root@angelsoma var]myisamchk -r,--recover [table 명] unique key를 제외한 대부분를 복구한다. [root@angelsoma var]myisamchk -n,--sort-recover [table 명] sorting하면서 테이블을 복구한다. 심지어 temporary 파일과 같은 아주 큰 파일역시 sorting하면서 복구한다. [root@angelsoma var]myisamchk -o,--safe-recover [table 명] -r 옵션보다 느리게 복구한다.그러나 좀더 섬세한 복구를 지원한다. [root@angelsoma var]myisamchk -q,--quick [table 명] 테이터 파일의 수정없이 복구한다. 5.기타 옵션 [root@angelsoma var]myisamchk -a,--analyze [table 명] key의 distribution 을 분석한다. 만약, distribution 을 산출하고 싶을경우에는 --verbose 나 --describe 라 는 옵션과 동행해서 확인할수있다. [root@angelsoma var]myisamchk -d,--description [table 명] 테이블에 대한 정보를 출력한다. [root@angelsoma var]myisamchk -S,--sort-index [table 명] index 블록을 sort한다. [root@angelsoma var]myisamchk -R[index번호],--sort-records [table 명] index 번호를 기준으로 인덱스를 정렬해준다. 6.검사중 아래의 메시지가출력되면 해당테이블을 사용중이라는 의미이므로 테 이블에 LOCK을 걸든가 데몬을 죽이고 나서 검사 및 복구를해야함. myisamchk: warning: 1 clients is using or hasn't closed the table properly 7.LOCK 걸기 myisamchk 는 테이블에대한 read 만 할수있으면 되기때문데 read 를 제외한 모든것에 lock을 걸면된다. mysql> lock tables [table 명] READ ; mysql> flush tables ; flush tables 는 mysql이 테이블의 내용을 메모리에만 보관하고 실제 테이 블파일에 기록을하지 않았을경우 실제 테이블파일에 기록하라는 의미이다 8.LOCK 풀기 mysql> unlock talbe; 9.Myisamchk 로 복구를 위한 LOCK 걸기 서비스를 죽이지않고 복구를 해야할경우는 write lock를 걸어주면된다. 복구는 write 를 해야하기때문에 write lock를 걸어줘야한다. mysql>lock tables [table명] write; mysql>flush tables; 10.LOCK 풀기 mysql> unlock table; |
| 블로그 > dohyah님의 블로그 http://blog.naver.com/dohyah/140009231142 | |
| 1.반드시 컴파일 하라! 10-30% 속도 향상 ! 소스를 가지고 컴파일 하세요. MySQL 메뉴얼에 따르면 10-30% 속도가 빠르다고 합니다. RPM 이나 바이너리 설치를 하지 마세요 ! 1-2.최신 버전을 사용하라 최신 버전이 좋은 점은 자동 튜닝 하는 것 입니다. 버그를 수정 하구요. 되도록 이면 최신 버전을 사용하세요 !! 2. HEAP 테이블이 가장 빠르다! 일반적으로 가장 많이 쓰이는 테이블 타입은 MyISAM 타입 입니다. MyISAM 타입은 무자게 빠르며, 대용량에도 강합니다. 그러나 트랜잭션은 지원되지 않습니다. 이노디비(InnoDB) 는 트랜잭션이 지원 됩니다. 쇼핑몰에서는 반드시 사용해야 합니다 ^^ HEAP 테이블 타입은 가장 빠르며, 단점은 메모리에 있기 때문에, MySQL에 중지 될 경우 모두 날아 갑니다. 검색을 하고 재검색을 다시 하는 경우, 임시 검색 테이블을 만들어 놓는 것도 좋은 방법입니다. HEAP 테이블 메뉴얼 ! http://www.mysql.com/doc/H/E/HEAP.html HEAP 테이블 만들기 ! mysql>CREATE TABLE email_addresses TYPE=HEAP ( ->email char(55) NOT NULL, ->name char (30) NOT NULL, ->PRIMARY KEY(email) ); 3.mysql 서버 top 보기 mysql 서버의 메모리 상황을 보여 주는 프로그램 입니다. 리눅스나 유닉스의 top 기능을 mysql 에서 가능하게 한것 입니다 . top 정보는 튜닝의 기본 이기 땜시 자주 자주 보아야 합니다. ^^ http://public.yahoo.com/~jzawodn/mytop/ PHP 소스 자료실에 파일 다운 로드 하시면 됩니다. 4.mysql_connect Vs mysql_pconnect 서버 메모리가 최소 2G 이상일 경우 mysql_pconnect 를 추천 함다 ! 연결을 계속 하지 않기 땜시 빠릅니다. ! 그러나 메모리가 2G 이하 일 경우는 mysql_connect 사용하세요 ! 5.int,smallint,tinyint 데이터형 ! int 는 굉장히 큰수 입니다. 4바이트를 차지 하구요. tinyint 는 몇백 까지만 됩니다. 1바이트 구요. 쓸데 없이 int 를 사용하지 마세용 !! 4바이트와 1바이트는 4배 차이 입니다.조그만것 1개 1개가 모여 서버 부하를 일으 킵니다.!! 데이터 량이 얼마만큼 들어가는지 체크 하고 데이터형을 선택 하세요 ^^ 만약 쓸데없는 데이터 형이다 싶으면 alter table 로 데이터 형을 바꾸세요 ! 6.인덱스의 사용 인덱스는 반드시 필요한 곳에만 넣으세요 ! 인덱스를 줄 경우 하드 용량을 더 차지 하기 때문에 속도를 떨어 뜨릴 수 있습니다. 모든 칼럼에 인덱스를 주는 것은 절대 추천 하지 않습니다. 1개의 테이블에 주키외에 2-3 개 이상의 인덱스는 주지 마세요! 주키는 당근 인덱스 입니다. ^^ CREATE TABLE albums ( id INTEGER NOT NULL AUTO_INCREMENT PRIMARY KEY, title VARCHAR(80)NOT NULL, INDEX title_idx (title) ); ☞Alter Table 로 인덱스 추가 ALTER TABLE albums ADD INDEX title_idx (title) 결합 인덱스의 경우 너무 많은 인덱스를 사용할 경우 CPU 오버헤드나 하드 오버헤드를 불러 일으 킵니다. 적당히 사용하세요 ^^ http://www.mysql.com/doc/I/n/Indexes.html http://www.mysql.com/doc/M/u/Multiple-column_indexes.html http://www.mysql.com/doc/O/R/ORDER_BY_optimisation.html 6-1. 바보 같은 인덱스의 사용 ? 인덱스는 %$search% 가 먹지 않습니다. 그런디 게시판 제목(Subject) 에 인덱스 걸어 놓고 , 검색을 %$search% 이렇게 하면 될까요? 인덱스 거나 안거나 똑같습니다. !! $search% 이렇게 사용하세요. 그런디.. $search% 사용하면 제목 처음 단어 밖에 검색이 안됩니다. 그렇다면 ? 다른 검색 방법은 ? 7.UDF의 사용 MySQL은 스토어드 프로시져 같은 개념이 존재 하지 않습니다. 그대신 C 언어로 만든 함수를 사용할 수 있습니다. 조금더 빠른 쿼리를 원한다면 UDF 를 사용해보세요 ! UDF 함수 보기 http://empyrean.lib.ndsu.nodak.edu/~nem/mysql/udf/ http://www.mysql.com/doc/A/d/Adding_functions.html 스토어드 프로시져가 먼뎅? 스토어드 프로시져는 쉽게 말해 MS-SQL 함수 입니다. 오라클에도 아마 있을검당..^^ 그러니까 게시판에서 내용을 넘길때나 불러 올때 mysql 쿼리가 3-4 번 정도 이루어 집니다. 또는 ms- sql 쿼리가 이루어지죵.. 3-4 번 정도 쿼리가 되면..그만큼 디비 접속이 잦아 지기 때문에.. 속도가 느려 집니다. 많게는 10번 정도의 insert into 와 update 가 이루어집니다. 그래서 ms - sql 자체 내에 인서트 함수 나 목록 보기 함수를 만들어 놓습니다. 글구 1번의 ms-sql 접속만 해서 인서트 함수를 불러서 처리하는 것입니다. 그렇기 때문에 2-3 번의 쿼리가 절약 되서 빠르다는 것이죵..ㅋㅋㅋ 또는 10번의 쿼리 할것을 MS-SQL 스토어드 프로시져를 1번만 호출 함으로 해서 디비 접속이 절약이 되죵..ㅌㅌ UDF 를 꼭 사용해야 하는가? 안해도 됩니다.만... 사용하면 좋은점 많습니다. 새로운 함수를 추가 할 수 있으므로 ^^ MS-SQL의 스토어드 프로시져 기능 비스므리 하게 사용할 수 도 있구요... UDF 나 MS-SQL 스토어드 프로시져의 사용법을 익히기 보다는 캐슁을 연구하세용 ^^ 동적인 PHP 를 정적인 HTML 로 만드는 방법을요... 또는 UDF 에서 MS-SQL 스토어드 프로시져 처럼 사용이 가능 합니다. 그 부분을 연구하세요. www.zdnet.co.kr 이나 www.zdnet.com 가시면 기사 파일이 1000,29920,2892.html 파일 이란것을 보게 됩 니다. 어키 구현된것일까요? zdnet 게네 들은 강좌를 원래 부터 HTML 로 만들어서 올리는 것일까용?? HTML 로 만드는 부분도 많이 생각 해야 합니다. 강좌가 1만개 라면, 1만개의 파일이 생성 됩니다. zdnet 의 경우는 조회수가 10만-20만을 넘는 초대형 사이트 이기 때문에 HTML 로 만드는 것이 퍼포먼스가 좋습니 다. UDF 배워 두면..남주지 않습니다. 8.조인보다는 쿼리를 나누어라! 조인(Join)하는 것보다 쿼리를 2개로 나누는 것이 속도가 빠릅니다. 조인을 생각 하기 이전에 쿼리를 나누는 것을 생각 하세요 ^^ 어쩔 수 없는 경우는 당근 조인 해야죠. 글고 서브쿼리는 아직 지원 안됩니다. Ms-SQL이나 오라클에서 서브쿼리 보다는 서브쿼리를 하지 않는 방향의 데이터 정규화를 하세요 ^^ 조인 보다 서브쿼리가 느리다. 서버 쿼리 보다는 조인을 사용하세요 ^^ 9.full text index와 search 3.23.23 부터 mysql 에서는 full text index 를 지원 합니다. 자세한 사항은 아래 ! http://www.mysql.com/documentation/mysql/bychapter/manual_Reference.html#Fulltext_Search http://www.mysql.com/doc/F/u/Fulltext_Fine-tuning.html 10. SELECT * FROM sometable SELECT * FROM sometable 에서 * 모든을 사용하는 것은 무식한 방법 입니다. 모든 칼럼을 불러오는 경우는 드물거든요. SELECT code,tadate,see FROM sometable 사용할 것만 불러 오세요 ^^ 11.데이터베이스 정규화 테이블을 아무렇게나 만들면 안됩니다. 데이터베이스 정규화 원칙에 의거, 테이블을 나눌것은 나누고 만드시는 것이 좋습니다. 제1 정규화, 제2 정규화 정도는 사용하셔야 합니다. 게시판을 만들때 아직도 테이블 1개에 만드시나요? 온라인 폴 만들때 , 테이블 1개에 만드시나요? 12.REPLACE INTO문 사용하기 REPLACE INTO albums VALUES (6, 'tood.net') insert 문대신에 replace 문을 사용해보세요. 메뉴얼 보시고 연구하세요 ^^ 주키일 경우 사용하시면 됩니다. 13. explain 사용하기 explain 를 사용하여 테이블의 키 값이 얼마나 잘 활용 되는지 알 수 있습니다. EXPLAIN SELECT, SHOW VARIABLES, SHOW STATUS, SHOW PROCESSLIST http://www.mysql.com/doc/E/X/EXPLAIN.html 17.BLOB과 TEXT는 분리하라 BLOB과 TEXT 칼럼은 테이블을 분리 하는 것이 좋다. 다른 칼럼의 내용 보다 크기 때문이다 ! OPTIMIZE TABLE 명령을 자주 사용해라 ! Not null 로 지정 하는 것이 빠르다. varchar 보다 char 이 훨빠르다. |
| 블로그 > 『해킹.... 속임수의 예술....』 http://blog.naver.com/zsup1343/60003542238 | |
| mysql 을 엑셀로...... 우선 mysql 에 접속하여 데이타를 저장합니다... 아마도 load data infile 라는 명령을 아시는 분은 아시겠죠.. ^^ 이 명령은 텍스트 파일을 데이타 베이스로 저장하기 위한 명령입니다.. 이 명령의 반대가.. 데이타를 텍스트로 저장..즉 select * into outfile '파일명' from 테이블 하시면.. 테이블의 자료가 텍스트 형식으로 저장이 됩니다.. 옵션으로는 fields terminated by '|' 구분자를 지정하여 주실수 있읍니다. 그렇게 되면...형식이 데이타|테이타|데이타|데이타 이런 형식으로 저장이 되겠죠... 옵션이 없으면 tab 형식으로 저장이 되고요.. 그럼.. 이 저장된 파일을 윈도우 쪽으로 옮긴후 엑셀을 열고.. 이 파일을 불러오기 합니다.. 그럼.. 엑셀에서 이 파일을 어떤 방식으로 불러올지 물어보더군요.... 기본 형식으로 저장하면.. 저장된 데이타들을 보실수 있으실 것입니다... 설명보다는 직접 해 보시면.. 쉽게 이해하실수 있으실 것입니다. 그럼..좋은 결과 있으시길 바라며... |
| 블로그 > 박군의 블로그 http://blog.naver.com/webmaster23/6332122 | |
정규화
데이터베이스의 설계에서 가장 중요한 것은 현실을 제대로 반영하는 것이며, 이를 어떻게 논리적으로 구성하는가를 결정하는 것입니다. 특히 관계형 데이터 모델에서는 데이터 값들이 2차원의 평면 테이블 형태로 표현하므로 어떤 릴레이션들이 필요하고, 어떤 애트리뷰트가 필요한가를 결정하는 것이 중요합니다.
이젠 앞서서 직관적으로 바라보았던 것들을 '정규화'라는 원리를 도입할 것입니다. 정규화는 관계형 데이터 모델에서 아주 중요한 역할을 하고 있습니다. 학자마다 정규화는 튜닝의 도구 또는 설계 검증의 도구이다라고 의견이 약간씩은 다르지만 결국은 같은 의미를 가지고 있습니다. 현실을 제대로 반영하는 것은 튜닝과 검증이라는 것을 모두 포함하고 있기 때문입니다.
데이터베이스 설계를 할 때 우리는 단계적인 사고방식을 가져야한다고 했습니다. 단계적인 사고 방식에서 윗 단계를 생각해 봅시다. 대부분은 설계의 초기단계에서 복잡한 생각을 하지 않는다고 나중에 누락되지는 않을까 하고 생각하는 분들이 많습니다. 그러나 이러한 것들은 정규화 과정이나 앞의 단계를 거치면서 데이터 모델링은 멋있게 틀을 잡아갑니다. 이렇게 틀을 잡아가는 것중 정규화는 그야말로 아주 큰 역할을 하는 것입니다. 앞에서 행했던 설계를 검증하고, 데이터의 중복을 없앤다 것 자체가 정보의 질을 높이고, 설계의 튜닝을 하는 것이니까요.
정규화란 속성이 제위치에 제대로 찾아가게끔 하는 것입니다. 정규화의 목적은 당연히 데이터의 중복의 최소화와 여러가지 이상(Anomaly)들을 제거함에 있습니다. 데이터가 중복되어 있으면 여러 문제를 일으킬 수 있습니다. 삽입, 삭제, 변경에서 나타는 이상들이 개발자를 괴롭히는 것입니다. 이것은 결국 속성이 제자리에 있지 않기 때문에 발생하는 중복의 문제점 때문이라고 할 수 있습니다.
정규화 과정은 속성간에 관계성, 데이터 종속성, 성능, 데이터베이스의일관성 유지등을 고려해야합니다. 정규화를 검증도구라고 하는 것도 설계가 잘못되면 일어날 수 있는 여러가지 문제점을 예방하는 차원이기 때문입니다. 또한 데이터의 중복을 없앤다는 자체가 엄청난 튜닝의 효과를 가지는 것입니다. 일단 데이터의 중복이 많은 설계는 먼가가 문제가 있는 설계입니다. 데이터베이스의 정의에서도 언급했듯이 데이터베이스는 중복의 최소화로 기존의 파일처리방식이나 수작업 방식에서 오는 정보의 질을 떨어뜨리는 문제점을 없애는 것입니다. 이러한 문제점을 좋은 정보의 질을 유지하기 위한 하나의 정형화된 도구 즉, 정규화를 통해 해결을 하게 되는 것입니다.
정규화는 데이터의 중복으로 인한 문제를 해결하기 위해서 속성들간에 종속성(Dependency)을 분석해서 기본적으로 하나의 릴레이션(테이블)에 표현하도록 분해를 하는 것입니다. 어떻게 보면 테이블을 무작정 쪼개는 것으로 보일 수도 있습니다. 그러나 테이블을 쪼개는 기준은 "함수적 종속"이란 개념으로 쪼개는 것입니다. 즉, 함수적 종속성을 파악한 다음 그 함수적 종속을 기본으로 해서 속성들을 하나의 테이블로 그룹짓는 것입니다.
함수적 종속
그럼 "함수적 종속" 이란 것이 무엇인가 살펴보도록 하겠습니다. 일단 함수라 하면 다음의 그림과 같이 나타낼 수 있습니다.
이것을 테이블로 표현한다면 다음과 같겠지요.
감이 약간 오시나요?? 일단 함수적 종속이란 말에서 함수라는 것에 대해서 살펴보도록 하겠습니다. 함수가 무엇인가요? 다름의 그림을 보고서 설명을 하도록 하겠습니다.
그림처럼 왼쪽은 2라는 원소가 두개가 들어 있습니다. 2를 어떤 함수에 집어 넣어야지 4가 될까요? 일반적으로 생각해 보면 2의 제곱을 구하는 함수에 값을 집어 넣는다면 4가 되겠지요. 그러나 역으로 4를 집어 넣는다면 16이 되버리는 것입니다. 즉, 2와 2는 4가 되기 위해서 함수적으로 종속되어 있는 것입니다. 결국 4는 2와 2가 4가 되기 위한 함수에 종속적이기 때문에 2의 제곱이라는 함수에 종속적이게 만드는 4는 "결정자"라고 부릅니다. 또한 2와 2를 "종속자"라고 합니다.
사실 이렇게 수학적으로 함수적 종속을 설명하였으나 정규화는 시스템을 구축하고자하는 조직내의 의미에 함수적 종속을 설명해야 합니다. 즉, 정규화는 관계형 모델에서 표현하고자 하는 주제가 동일한 속성들끼리 뭉쳐져 있는 것입니다. 그러므로 설계의 초기부터 나타내고 자하는 정보를 의미론적으로 묶는다면 정규화라는 과정의 설계의 검증도구가 되는 것입니다.
위의 예에서 2를 Y로 하고 4를 X라 한다면 함수적 종속의 표현은 "X Y" 로 표기합니다. 이러한 표현을 실제의 예를 들어서 살펴보겠습니다.
학생 릴레이션에서 ...
학번 이름 학번 학과 학번 학년
위에서 보는 바와 같이 학번은 이름, 학과, 학년을 결정하고 있습니다. 즉, 학생 릴레이션에서 각각의 학생을 유일하게 구분지을 수 있는 속성은 학번으로 학번은 기본키의 역할을 하는 속성입니다. 즉, 이름만 가지고는 각각의 학생을 알 수 없다는 것입니다. 제가 옛날에 휴학을 하려고 했는데 시간이 없어서 조교님께 휴학 신청을 대신해달라고 한 적이 있었습니다. 그런데 저와 같은 이름을 가진 다른 사람이 있었는데 그 사람으로 휴학을 한적이 있어서 상당히 난감했던 적이 있습니다. 즉, 저의 이름인 "이재학" 만 가지고는 정확성이 있는 정보가 될 수 없던 것입니다. 만약 교수님께서 "이재학"을 불러오라 라고 한다면 이미 과에 "이재학"이란 이름을 가진 사람이 2명이라는 것을 아는 사람은 학번을 교수님께 되물을 것입니다. 이렇듯 이름은 학번에 종속되어 있다는 것입니다. 이름이 이재학이고, 학과가 정보통신공학과이고, 4학년인 학생은 저 말고도 한명이 더 있습니다. 즉, 이것들은 학번에 종속적이라는 것입니다.
테이블로 표현한 것을 가지고 좀더 살펴보도록 하겠습니다.
9555023, 이재학, 4학년, 정보통신공학과 라는 것은 한명의 학생에 대햔 데이터입니다. 학번, 이름, 학년, 학과중에 대표성을 띄고 있는 것은 학번이고, [9555023, 이재학], [9555023, 4학년], [9555023, 정보통신] 이라고 해야지만 정확한 정보를 표현할 수가 있는 것이죠. 앞에서 언급했듯이 [이재학, 4학년, 정보통신]이라고 해서 정확한 정보가 되는 것일까요? 당연히 학번이 9555023인 학생과 학번이 9839011인 학생을 구별하지 못하는데 문제가 있습니다.
이렇듯 학번은 이름, 학년, 학과를 결정하고, 이름, 학년, 학과는 학번에 종속적입니다. 이렇게 데이터에 대한 의미를 표현한 것을 함수적 종속이라고 합니다.
<참고> 함수 종속에 대한 증명된 추론 규칙 (R 릴레이션) (데이터베이스시스템, 이석호, 정익사)
R1: (반사규칙) A B 이면 A B 이다. R2: (첨가규칙) A B 이면 AC BC 이고 AC B 이다. R3: (이행규칙) A B 이고 B C 이면 A C 이다. R4: (분해규칙) A BC 이면 A B 이다. R5: (결합규칙) A B 이고 A C 이면 A BC 이다.
정규화는 이러한 "함수적 종속"을 기본 원칙으로 하나의 의미를 가지는 집합으로 나누는 작업입니다. 정규화는 1차 정규화, 2차 정규화, 3차 정규화, 보이스/코드 정규화, 4차 정규화, 5차 정규화, 도메인/키 정규화가 있습니다. 이 순서가 높아지는 단계의 정규화일수록 무결성은 강화되나 과도하게 테이블이 쪼개지므로 쓸 때 없는 부하가 걸릴 수 있습니다. 그러므로 현실을 감안해서 어느 정도 수준의 정규화까지 행해야 하는가를 결정해야 합니다. 보통 실무에서는 3차 정규화와 보이스/코드 정규화까지 합니다. 기본으로 3차 정규화까지는 해야 하며, 3차 정규화 과정을 마치고도 사용자의 요구사항에 의해서 여러가지 이상들이 발생할 요지가 있다면 더 높은 차원의 정규화를 해야 합니다. 이제 각 단계별 정규화에 대해서 설명하도록 하겠습니다.
1차 정규화
하나의 릴레이션은 어떤 도메인의 집합입니다. 각각의 속성은 해당 도메인에 속하는 단지 하나의 값을 가져야 합니다. 이것이 1차 정규화 이며, 실제로 1차 정규화도 거치지 않은 테이블이 많이 존재합니다. 예를 들면 다중값 속성들이 그대로 표현될 때 정규화된 테이블이 아닌 즉, 비정규화 테이블인 것입니다. 사원테이블에 사번, 이름, 보유기술, 월급의 속성이 있는데 보유기술은 여러 개를 가질 수 있다는 현실을 생각해 보도록 하겠습니다. 일반적으로 문서를 만들면 다음과 같은 문서가 나올 수 있습니다. 보유기술에서 하나의 속성값에 여러 개의 값이 들어간 것을 볼 수 있습니다. 이러한 표현은 비정규화 된 테이블입니다. 여기서 기본키는 사원번호입니다.
그렇다고 다음과 같이 보유기술을 옆으로 펼친다고 해서 달라지는 것은 없습니다. 이도 역시 1차 정규화된 테이블이 아니라고 볼 수 있습니다. 의미상으로 보유기술1, 보유기술2, 보유기술3는 그냥 보유기술의 종류일 뿐입니다. 그러니 하나의 속성에 여러 개의 값을 다른 표현으로 한 것 뿐입니다.
어떤 독자분은 보유기술 속성에 속성값을 넣는데 콤마로 구분하면 어떻겠냐? 라는 생각을 가질 수도 있습니다. 만약 사원번호 1111 인 사원의 보유기술을 하나더 추가하려면 기본키가 "사원번호" 이므로 "사원번호"가 1111 인 사원이 추가되지 못하는 것을 알 수 있습니다. 즉, 다음과 같은 그림이 되어 삽입을 할 수 없는 형태가 되는 것입니다.
이제 본격적인 정규화에 대해서 알아보겠습니다. 아래의 테이블은 각각의 학생에 대해서 각각의 속성마다 단일값을 가지고 있으므로 1차 정규화된 테이블이 입니다. 여기서 독자분들은 함수적 종속관계를 찾아보아야 할 것입니다. 여러분은 찾아낸 함수적 종속성을 바탕으로 데이터가 많이 중복되어 있고, 그 데이터의 중복으로 인한 여러가지 문제점(이상)들을 찾아내어야 합니다.
이 테이블의 함수적 종속 다이어그램의 다음과 같습니다.
함수적 종속 다이어그램에서 보는 바와 같이 학번은 학생명과 학년을 결정하고, 학번은 학과를 결정합니다. 또한 수강코드는 담당교수와 과목명을 결정합니다. 각각의 학생은 자신이 수강신청한 과목의 성적등급을 알기 위해서 학번과 수강코드가 필요합니다. 담당교수는 학과를 결정합니다. 여기서 자칫 잘못하면 학과가 담당교수를 결정할 수 있다고 볼 수 있는데 하나의 학과에 소속된 교수는 여러명인 것이 보입니다. 즉, 지도교수가 학과를 결정하는 것이지 학과가 교수를 결정하는 것이 아닙니다.
이제 1차정규화된 테이블을 가지고 나타나는 문제점을 살펴보도록 하겠습니다. 이러한 문제점은 함수적 종속과 관련하여 찾아보아야 합니다.
이 테이블은 학번만 가지고는 어떤 과목의 성적의 등급이 얼마인지를 모릅니다. 그러므로 이 테이블의 기본키는 학번 + 수강코드입니다. 여기서 주의할 것은 수강코드라는 속성의 이름이 수강을 해야만 하는 코드가 아니라는 사실입니다. 즉, 수강할때 그 과목을 나타내는 과목의 고유번호응 나타내는 것입니다.
2차 정규화
앞서서 삽입, 삭제, 갱신 이상들이 일어 날 수 있다는 것을 보았습니다. 1차 정규화된 테이블에서 이러한 문제점이 일어나는 원인이 무엇일까요? 원인은 바로 기본키가 아닌 각각의 속성들이 기본키에 종속적이지 않고, 부분적으로 함수 종속이 되기 때문입니다. 즉, 기본키를 제외한 모든 속성이 기본키에 함수적 종속이 아니기 때문입니다. 이러한 문제를 해결하기 위해서는 기본키에 함수 종속을 시킨 것 끼리 따로 테이블을 만들어야 합니다. 2차 정규화된 테이블은 다음과 같습니다. ( 테이블 밑은 점(...)은 생각치 않도록 하겠습니다. )
2차 정규화의 결과로 위와 같은 3개의 테이블이 나왔습니다. 학생과 수강과목은 다:다의 관계를 맺고 있기 때문에 학생의 학번과 수강과목의 수강코드가 합쳐진 것을 기본키로 하여 학생 테이블과 수강과목 테이블을 연관지어 주고 있습니다. 사실 데이터 모델링의 초기단계부터 차근 차근 진행해 오면서 엔티티만 제대로 도출해 냈다면 이와 같은 2차 정규화 작업은 필요가 없습니다. 그러나 이와 같은 검증된 원리를 알고 있다면 애매모호 함이 없어지고, 좀더 정확한 정보를 산출하는 정보시스템이 만들어 질 수 있는 것입니다.
학생 테이블과 수강과목 테이블에 학과라는 속성이 중복되어 존재하는 것이 보입니다. 이것은 어떤 다른 엔티티 집합이 더 존재한다는 것을 의미합니다. 즉, "학과" 엔티티가 "학생"과 "수강과목"과 관계를 맺고 있다는 것입니다. 위의 테이블을 볼 때 학과와 관련된 엔티티와 학생, 수강과목은 1:다의 관계를 맺고 있음을 알 수 있습니다. 즉,
학과 : 학생 1 : 다 학과 : 수강과목 1 : 다
의 관계입니다. (사실 더많은 객관적인 업무규칙이 파악되어야 정확히 알수 있습니다.) 그러므로 속성의 이름은 학과보다는 "학과명"이라고 하는 것이 더 명확하겠지요. 그러나 이 단원에서는 다른 엔티티 집합은 생각치 않고, 이에 대한 고려는 다음 단원에서 하겠습니다. 단지 이것은 정규화를 위한 예제라는 것을 염두해 두시기 바랍니다.
이제는 어느정도 속성들이 자신이 있어야 할 곳에 배치된 것으로 보입니다. 그러나 이러한 2차 정규화 테이블에도 이상들이 존재합니다. 이러한이상들을 살펴보도록 하겠습니다.
2차 정규화된 테이블에서 이상이 일어나는 이유는 기본키가 아닌 다른 속성들 간에 함수적 종속이 일어나기 때문입니다. 이렇게기본키가 아닌 속성들끼리의 종속성을 가지는 것은 이행 종속(Transitive Function Dependency) 라고 합니다. 이러한 개념으로 위의 테이블에서 일어날 수 있는 문제점을 찾아보록 하겠습니다. 먼저 문제의 이행 종속이 일어나고 있는 테이블을 추려내야 합니다. 앞서서 그려본 함수적 종속 다이어그램에서와 같이 이행 종속이 일어나고 있는 테이블은 수강과목 테이블입니다.
삽입이상: 각 과목을 담당하는 교수가 특정 학과에 속한다는 사실을 삽입하려 할 때 과목이 존재하지 않는다면 이 사실을 삽입할 수 없습니다. 즉, 각각의 행을 구분할 수 있는 대표성을 지닌 속성(기본키)가 존재하지 않으므로 삽입이 불가능하다는 것입니다. 기본키는 수강과목 테이블에서 반드시 들어가야만 하는 것인데 이를 무시한채 다른 속성값을 삽입하려 한 것이 문제입니다.
삭제이상: 만약 해당 학과의 커리큘럼이 바뀌어 오상훈 교수가 담당하고 있는 과목인 "자료구조"라는 과목이 없어진다면 오상훈 교수가 정보통신공학과에 소속된다는 사실도 없어지게 됩니다. 오상훈 교수가 정보통신공학과에 소속된다는 사실은 이행종속이 일어나고 있다는 것이며, 역시 2차 정규화된 테이블에서 일어나는 삭제이상도 이행 종속때문이라는 것을 알 수 있습니다.
갱신이상: 만약 박덕규 교수의 소속 학과가 정보통신에서 다른 학과로 변경된다면 박덕규 교수에 해당되는 학과에 대한 속성값을 모두 변경시켜 주어야 합니다. 역시 이행종속이 일어나서 일어나는 이상현상입니다.
3차 정규화
2차 정규화된 테이블에서 이행 종속에 의해서 여러 가지 이상현상이 발생되는 것을 보았습니다. 이러한 여러 이상현상을 제거하려면 어떻게 해야 할까요? 당연히 이상현상의 원인이 되었던 이행종속을 없애면 됩니다. 어떻게 없애야 할까요? 당연히 이행종속을 일으키는 속성들을 묶어서 그룹지어 주면 문제는 해결됩니다.
이렇게 이행 종속성을 제거한 테이블은 3차 정규화된 테이블입니다. 만약 독자분들 중에 여기까지 대충 읽어 보신분들은 아마도 정규화란 것이 테이블을 쪼개는 것이구나 라고 생각하시는 분들도 계실겁니다. 그러나 테이블을 쪼갠다는 개념을 갖지 말고, 좀더 세부적으로 관련성이 많은 것끼리 새로운 그룹을 만드는 개념으로 정규화를 생각하셔야 합니다.
<쉬어가기>
자존심... 여러분은 느껴보셨는지요? 공대인이 마음이 닫혀있다는 것을... 얼마전 웹상에서 알게된 친구가 저에게 메신저로 호출을 하더군요. 그래서 왜 그러느냐고 했더니 지금 큰일났다고 하더군요. 다시 왜 그러냐고 물었더니 지금 자기가 하고 있는 프로젝트가 원래 D사 의 프로젝트인데 하청으로 받아서 하고 있는데, D사 사람이 와서 DB설계 개판(?)으로 했다고 하면서 엄청 깨졌다고 하더군요. 그러더니이거 DB 설계 다시해서 그쪽 사람과 협상해야 한다고 하소연을 했습니다. 그래서 한번 보자고 했습니다. ㅡㅡ;;
저는 그 DB설계 해논 것을 보고 이게 도대체 머냐? 그럴만 하다 라고 했습니다. 그랬더니 자기자신도 모르는 상태에서 했기 때문에 그럴만 하다라는 것을 인정하면서도 너무나도 화가 난다고 하는 것이 였습니다. 왜 화가 나는 것일까요? 자신이 해논 것에 대한 쓸 때 없는 자존심 때문일까요?
이상스럽게 이쪽 분야에서 일하는 사람이나 공부하는 사람들은 지는 것을 싫어합니다. 사실 게임도 아닌데 많은 사람들이 자신이 제시한 솔루션이 가장 옳다라고 우겨서(?) 이기고자하는 경향이 있습니다.(물론 필자도 그런 경향이 매우 짙게 나타납니다. 모르는 것도 전에 알던 지식을 이용해서 논리적으로 엮어서 아는 척하는 합니다. ㅡㅡ;;) 정보기술분야는 너무나도 빨리 발전하고 있습니다. 거의 대부분의 사람이 따라가기 바쁘지요. 물론 필자도 따라가기가 너무 힘듭니다. 그래서 매일 꾀죄죄한 모습으로 학교에서 중국음식에 길들여지면서 고생하는 이유일지도 모르겠습니다. 다음 그림을
여러분은 마음을 열고 다른 사람의 것을 받아들일 수 있어야합니다. 너무나도 빨리 발전하고 있는 기술을 따라가는데 가장 빠른 지름길은 사람과 사람이 나누는 Communication 일것입니다.
보이스/코드 정규화
3차 정규화도 여러가지 이상이 존재합니다. 그렇다면 이상이 발생하지 않는 정규화 과정은 어떤거냐고 의문을 가지는 분도 있을 겁니다. 이상이 발생하지 않는 정규화는 키/도메인 정규화입니다. 이것은 증명은 되었으나, 키/도메인 정규화 테이블을 만드는 구체적인 방법을 발견하지 못했기 때문에 실무에서 직관적으로 사용되는 방법이기도 합니다. 그러나 보통 실무에서는 3차 정규화과정이나 다음에 할 보이스/코드 정규화까지 합니다. 그 이유는 일반적으로 4차 정규화나 5차 정규화 과정을 거쳐야 하는 상황은 거의 발생하지 않기 때문입니다. 이 책에서는 보이스/코드 정규화 과정까지만 언급하겠습니다. 만약 보이스/코드 정규화 과정을 거쳤으나 사용자가 원하는 작업을 수행할 때 이상이 발생한다면 4차 정규화 과정을 거쳐야 할 것입니다. 4차, 5차 정규화는 다른 책을 참고하셔야 할 것입니다.
이제 위의 3차 정규화를 거친 테이블에 대한 이상현상이 발생하는 원인을 분석하고 보이스/코드 정규화에 대해서 언급하도록 하겠습니다.
3차 정규화 과정을 거치 테이블에서 이상현상을 발생시키는 원인은 후보키들이 중첩되어 있다는 것 때문입니다. 후보키는 기본키가 될 수 있는 자격이 있는 속성 또는 속성들입니다. 즉, 하나의 릴레이션에 여러 개의 후보키가 존재하는데 하나 또는 여러 개의 속성이 중첩되어서 후보키될 때 이상현상이 발생할 수 있다는 것입니다. 보이스/코드 정규화 과정은 바로 이러한 문제점을 해결하는 것입니다. 이러한 의미에서 볼 때 보이스/코드 정규형은 엄격한 3차 정규형이라고도 합니다.
보이스/코드 정규형은 릴레이션의 모든 결정자가 후보키이면 보이스/코드 정규형이라고 보는 것입니다. 결정자라는 개념은 어떤 속성을 함수적으로 완전히 종속시키는 속성을 의미합니다. 만약 다음의 업무 규칙이 존재하는 테이블이 있다고 가정 한다면
-. 하나의 과목을 여러 교수가 담당할 수 있다. -. 각 교수는 하나의 과목만을 담당한다. -. 각각의 학생은 같은 과목명을 가진 다른 과목을 수강하지 못한다.
앞서서 언급한 3차 정규화의 문제점인 후보키의 일부가 되는 속성인 "학번"이 중첩되어 있는 것이 보입니다. 즉, 수강_교수 릴레이션의 후보키는 "학번 + 과목명" , "학번 + 담당교수" 입니다. 이 후보키중 "학번 + 과목명"을 기본키라고 가정하겠습니다. 함수 종속 다이어그램에서 보는 바와 같이 "학번 + 과목명"은 "담당교수"를 결정하고, "담당교수"는 "과목명"을 결정합니다. 이런 구조를 가지고 있는 릴레이션의 문제점을 파악해 보도록 하겠습니다.
삽입이상: 만약 이현태 교수도 자료구조를 담당하게 되었다면 수강신청을 한 학생이 있어야만 이와 같은 사실을 입력할 수 있습니다. 만약 "담당교수"의 의마가 해당 과목을 담당하고, 또한 그 학생에 대한 생활지도 등의 "지도"를 할 수 있다면(여기서는 담당과목을 수강하지 않은 학생도 지도할 수 있다는 가정), 과목을 수강하지 않은 학생은 지도교수가 누구인지 결정을 할 수 없게 됩니다.
삭제이상: 학번이 "9655032" 인 학생이 자료구조의 수강 취소를 한다면 오용선 교수가 자료구조를 담당하고 있다는 사실도 함께 삭제됩니다. 이 뿐만 아니라 다른 과목들도 마찬가지로 수강하는 학생이 수강을 취소한다면 과목에 대한 담당교수도 같이 삭제되므로 이상현상이 일어납니다. 만약 다른 수강 신청자가 있다면 이와 같은 사실은 같이 삭제되지 않으나 현재 상황으로 볼 때 어떤 교수가 어떤 과목을 담당하고 있는지를 나타내는 것이 한 개의 투플(행)뿐이기 때문에 이러한 문제를 해결되어야 합니다.
갱신이상: 만약 이현태 교수가 "DB" 에서 "네트웍 프로그래밍"으로 담당과목이 바뀌었다면 3개의 투플(행)을 모두 변경해주어야 합니다.
이러한 문제점은 보이스/코드 정규화 과정을 거치면 해결되는 문제입니다. 즉, "모든 결정자가 후보키" 가 되게 하면 되는 것입니다. 다음은 보이스/코드 정규화의 결과입니다.
이제 여러분은 1차 정규화에서 3차 정규화 까지를 종합적으로 살펴볼 필요가 있습니다. 즉, 이러한 원리만 알고 있다면 바로 3차 정규화 또는 보이스/코드 정규화까지 직접 도출이 가능합니다. 직접 도출하는 예를 들어 보겠습니다. 다음과 같은 스키마가 존재하다고 가정하겠습니다.
대출 (대출번호, 고객명, 지점명, 지점위치, 자산, 대출합계)
이 스카마는 어떤 은행은 대출에 관련된 스키마입니다. 이 스키마를 가지고 함수적 종속만 파악한다면 나머지 보이스/코드 정규형을 도출하는 과정은 간단합니다. 다음은 이 스키마에 대한 함수적 종속을 나타내는 것입니다.
<함수적 종속> 지점명 자산 지정명 지점위치 대출번호 대출합계 대출번호 지점명
도출한 R1, R2, R3, R4, R5는 모두 보이스/코드 정규형을 만족합니다. 각각의릴레이션의 모든 결정자가 후보키입니다. 그러나 이렇게 너무 불필요한 정규화는 결과적으로 성능을 떨어뜨릴 수 있습니다. 그러므로 다음과 같은 통합작업을 거쳐야 합니다.
결과적으로 R1(지점명, 자산), R2(지점명, 지점위치), R3(대출번호, 대출합계), R4(대출번호, 지점명), R5(대출번호, 고객명)으로 일단은 테이블을 최대한 분해하였습니다. 그러나 R1과 R2는 기본키가 같으므로 통합할 수 있습니다. 그러므로 R1_2 (지점명, 자산, 지점위치) 로 통합되고, R3와 R4, R5가 기본키가 같으나 R3, R4와 R5는 은행(R3, R4)과 고객(R5)으로 서로 다른 것을 나타내므로 R3와 R4는 통합되고, R5는 독립적으로 존재하게 됩니다. 즉, (R3, R4)와 R5는 표현하려는 정보가 틀리기 때문에 통합이 불가능합니다. 마지막에 나온 R5는 원래 정규화되기 전의 원래 테이블의 기본키가 됩니다. 결과적으로 다음과 같이 보이스/코드 정규화가 이루어졌습니다.
R1_2 (지점명, 자산, 지점위치) R3_4 (대출번호, 지점명, 대출합계) R5 (대출번호, 고객명)
결과적으로 정규화라는 과정은 함수적 종속이라는 하나의 원칙으로 관련성으로 속성들을 묶어서 데이터의 중복을 없애고, 데이터의 중복에 의한 여러가지 이상현상을 없애는 유용한 도구입니다. 데이터의 중복이 최소화되는 자체는 시스템이 가장 가벼운 데이터를 가지고 처리하기 때문에 전체적인 시스템의 성능이 높아지기도 하는 것입니다.
키/도메인 정규화
'정규화란것은 '함수적 종속'관계를 파악하는 것입니다. 이 종속관계를 파악하여 속성이 원래 갈 자리에 가게 하는 것입니다. 즉, 주제에 맞는 한 객체가 관련된 업무에 관한 속성들이 있어야 할 곳에 있게 하는 것입니다. 우리는 1차 정규화에서 보이스/코드 정규화까지 알아보았습니다. 보통 실무에서는 3차 정규화나 보이스/코드 정규화 때에 따라서는 아주 가끔씩 4차정규화를 행합니다.
그러나 검증은 되었으나 그 방법이 찾아지지 않은 키/도메인 정규화를 이 글에서 이야기하고자 합니다. 키(key)라는 것은 객체를 유일하게 구별할 수 있는 속성중에 가장 관련된 대표적인 것을 이야기 합니다. 이 키에 함수적으로 모두 종속되고, 속성의 도메인이 맞다면 즉, 모든 제약이 키와 도메인의 정의에 따른 논리적인 결과인 것은 모두 키/도메인 정규화인 것입니다. 이것은 완벽한 정규화입니다. 3차 정규형은 기본키에 모두 함수적 종속적인 것들로 테이블을 분리하고, 기본키가 아닌 속성들끼리의 종속성 즉, 이행종속을 일으키는 속성들을 다른 테이블로 옮기고 그 테이블에 기본키를 정의할 수 있으면 됩니다. 이와 같이 분리된 테이블은 기본키를 가지게 됩니다. 이러한 개념으로 테이블을 봤을때 데이타가 중복되어 나타나는 것들 잘 살펴보면, 왜 중복이 일어났는지 알수 있을 것입니다.
정규화의 해법들이 키/도메인 정규화 빼고는 모두 나와있습니다. 그러나 직관적으로 바라본다면 해법이 나와 있지는 않지만 키/도메인 정규화가 더 쉽습니다. 또한 초기에 엔티티를 선정할때 우리가 시스템화 하고자하는 관련된 것들끼리 모인 즉, 엔티티를 잘 선정한다면 직관적인 관점에서 3차정규화는 충분히 할 수 있으리라 생각합니다. 그렇다고 정규화 과정을 무시해서는 안됩니다. 이렇게 직관적으로 설계를 하면서 나갈때는 정규화는 검증도구가 되는 것입니다. 학자에 따라서 정규화는 검증도구다 또는 튜닝도구다라고 하는 의견들이 분분합니다. 그러나 정규화는 반드시 필요한 것이 틀림이 없습니다.
도메인/키 정규화에서 중요한 단어는 제약, 키, 도메인입니다. 한가지 주의할 것은 제약에 시간의 개념을 뺏다는 것입니다. 엑기스만 뽑는다면 키와 도메인에 대한 제약을 준수시켰을때 모든 제약이 준수되는 릴레이션은 키/도메인 정규형입니다.
다시 핵심단어 키, 도메인, 제약 이 세가지의 관점에서 살펴보겠습니다. 키라는 것은 객체들을 유일하게 구분지어 주는 속성입니다. 즉, 속성들중 대표하는 것을 말합니다. 이 속성들이 가질수 있는 값들의 범위를 정의한 것이 바로 도메인입니다. 독자들중에 아시는 분이 별로 없으시겠지만 푸리에변환 같은 것을 보면 시간 도메인에서 주파수도메인으로 주파수 도메인에서 시간 도메인으로 변환을 할 수 있습니다. 시간 도메인에서 본다면 이 값들은 절대로 변환과정을 거치지 않고는 시간이라는 단위밖에 가지지 못하는 것입니다. 실제로 주민번호를 본다면 생년월일 담에 오는 1이란 숫자는 남자밖에 가지지 못하는 숫자입니다. 이 도메인을 벗어난다면 현실에 맞지 않게 되는 것입니다. 누누히 얘기하지만 데이타베이스는 현실을 최대한 반영하는 것입니다.
정리하자면 키라는 것은 "unique + not null + 대표성" 입니다. 도메인은 앞에서 얘기한 것처럼 속성이 가질수 있는 값의 범위이고 가질수 있는 꼭 그것을 가져야만 하는 의미입니다. 이것은 현실의 제약이라고 볼수 있으며, 이러한 제약이 지켜진다면 이것은 완벽한 이상이 없는 정규형입니다. 정규화의 정리
이제 앞에서 살펴보았던 정규화에 대해서 의미로만 따져도록 하겠습니다. 필자의 경우는 정규화 과정은 검증도구로 사용하는 편입니다. 사실 함수적 종속이란 것이 조직의 범위내에서 통용되는 의미에 따라 틀려집니다. 그러므로 모델링을 하기전 단계에서부터 정보시스템을 구축하려는 조직에서 사용되는 정보의 의미를 파악하는 것이 더 중요하다고 합니다.
3차 정규화된 테이블을 보면 테이블마다 어떤 정보들을 나타내기 위해서 데이터 들이 뭉쳐있습니다. 즉, 각각의 속성들이 뭉쳐서 어떠한 하나의 정보(의미)를 만들어 내기 때문에 그 의미만 잘 파악한다면 앞에서 행했던 것처럼 바로 보이스/코드 정규화까지 직접 도출이 가능한 것입니다. 그냥 어떤 "의미"를 나타내기 위해서 그룹짓는 과정이라고 하기엔 너무 애매모호 합니다. 그래서 함수적 종속이란 개념을 도입하여 누구나 고개를 끄덕이게 만든 것이 정규화입니다.
독자가 파악해야 할 것은 사용자의 정보가 무엇인지 정확하게 판단하여야 할 것입니다. 만약 사용자의 요구사항이 정확하게 파악되면, 그 요구사항을 정확히 반영하기 위해서 엔티티를 도출하고, 각각의 속성들을 배치해야 합니다. 엔티티는 속성의 집합이기도 합니다. 하나의 엔티티가 다른 엔티티와 관계를 맺고, 어떠한 정보를 만들어 낼 수 있습니다.
일반적으로 데이터 모델링은 하향식(Top-Down)의 방식으로 설계를 하고, 정규화를 통한 하향식(Bottom-up) 방식으로 검증을 하는 방법론을 사용합니다. 이제 속성을 가지고 다음 그림을 살펴보도록 하겠습니다.
제일 먼저 파악해야 할 것은 "관련성" 입니다. 릴레이션이란 것이 속성들이 어떠한 관련성에 묶여서 있는 모습입니다. 그러니 관련성이라는 의미는 매우 중요한 것입니다. 이것은 기본키와의 관련성입니다. 하나의 개체( 학생으로 하였을 경우 학번이 9555023인 학생 하나는 인스턴스입니다.)를 대표하는 것이 기본키이기 때문입니다.
두번째는 파악해야 할 것은 속성의 도메인입니다. 각각의 속성은 가질 수 있는 값의 범위 즉, 도메인을 가지고 있습니다. 이 도메인에서 표현할 수 있는 속성값들을 대표할 수 있는 것들을 찾는 것입니다. 이 도메인도 관련된 엔티티의 범위를 가지기 때문에 관련성이라는 것은 매우 중요합니다.
의미상으로 볼 때 학번과 학생명이 같은 객체의 다른 표현인 것을 알 수 있습니다. 그러나 한 학년에 속하는 학생이 여러명인 것을 알 수 있지만, 학년자체는 독립적으로 존재할 수 있는 즉, 엔티티가 아니라 속성이라는 것입니다. 결과적으로 이 릴레이션은 "학생" 엔티티 집합이 포함된 것입니다.
이러한 방식으로 속성값을 살펴보면 위의 그림이 나올 수 있습니다. 그림에서 학과명과 관련된 것을 살펴보면, 일단 학번이 이름과 학년을 결정하는 것은 앞에서 체크었으므로 이 두 속성은 제외하고 학번으로만 생각해보도록 하겠습니다. 학번이 학과명을 결정하나요? 이 부분은 상당한 혼돈의 여지가 있습니다. 그러나 좀더 원천적으로 생각하면 데이터베이스 시스템을 개발하려는 도메인이 무엇인가요? 바로 "학교"입니다. 즉, 학교에는 기본적으로 "학생"과 "학과"가 존재해야 "학교"가 존재할 수 있는 것입니다. 즉, 학과와 학생은 기본엔티티 집합인 것입니다. 이렇게 "닭이 먼저냐? 달걀이 먼저냐?" 라고 따지는 상황이 온다면 이것은 기본엔티티 집합입니다. 그러므로 학과명은 "학과" 엔티티 집합의 속성입니다. 그러므로 이것은 외부키인 것입니다. 그렇다면다른 속성은 어떨까요? 당연히 다른 속성들도 따져볼 것이 못되는 것입니다. 만약 관련이 있다면 그것은 외부키로 의 기능을 하는 속성입니다.
결과적으로 이 테이블에서 도출할 수 있는 엔티티 집합은 "학생", "수강(또는 과목)", "학과", "교수" 입니다. "학생" 과 "수강" 은 다:다의 관계를 맺고 있으므로 "수강코드, 학번, 등급" 은 이 다:다의 관계를 해소한 것이 되는 것입니다.
이렇게 엔티티와 속성과 관계를 도?하는 것은 데이터 모델리의 핵심입니다. 이와 같은 기본적인 것만 확실히 파악이 된다면 정규화는 데이터 모델링의 검증의 도구와 튜닝의 도구로 써 훌륭한 역할을 할 것입니다. |
















| 카페 > 디자인같은 프로그램 강좌 / 디플타임님 http://cafe.naver.com/dptime/24 | |
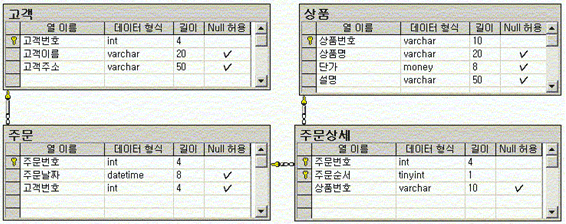
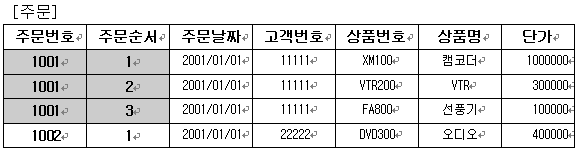
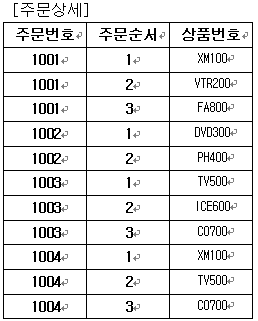
정규화(NORMALIZATION) 테이블은 행(row)들과 열(column)들로 구성된 하나의 실체이며 데이터의 컬렉션인 엔티티(entity)이다. 하나의 테이블은 다른 테이블들과의 관계(relationship)를 맺을 수 있다. 이 관계 구성의 논리화가 바로 정규화로써 이루어지게 된다. 설계의 출발은 데이터 저장 매체인 엔티티(테이블)들을 구성하는 것이다. 일단은 서비스 흐름에서 찾아지는 기본적인 엔티티를 찾아서 그 엔티티로부터 정규화를 거치는 예를 들어 보도록 한다. 전자제품 대리점에서 고객이 물건을 주문하면 그 고객의 주문 정보가 생성이 된다. 바로 첫번째 엔티티가 생성이 되는 것이다. 그러면 ‘주문’이라는 엔티티에는 어떠한 항목들(필드 설정)이 들어가야하는지 다음의 테이블로 구현을 했다.
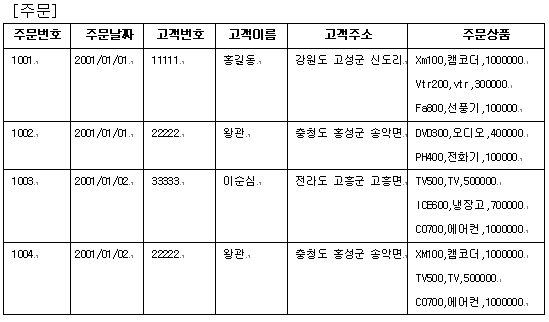
1차 정규형식(1NF, first normal form) 중복된 데이터를 찾아보기 위해 ‘주문’테이블에 다음처럼 발생 가능한 데이터를 입력해 보자. 이 테이블에는 하나의 주문에 대한 모든 정보가 다 들어 있다. 고로, 중복된 데이터가 있을수 있는 것이 된다.
이 테이블은 주문에 대한 자세한 정보가 들어가 있다고 했다. 그러면 왜 이테이블을 분할해야 하는가? 그 이유는 다음과 같다. ㄱ. 데이터를 여러 번 저장하는 것은 공간 낭비 ㄴ. 반복적인 데이터가 존재한다는 것은 데이터의 이동량이 더 크게 된다. 따라서 데이터 버스나 네트워크 대역폭에 더 많은 부담이 생긴다. 이는 전반적인 성능에 상당한 악영향을 미친다. ㄷ. 반복 데이터들 간의 서로 모순된 데이터를 저장할 수 있다. 이것은 데이터 무결성이 깨져버린 것이다.
분리시키는 과정을 거쳐야 하기에 속도가 떨어지게 된다.
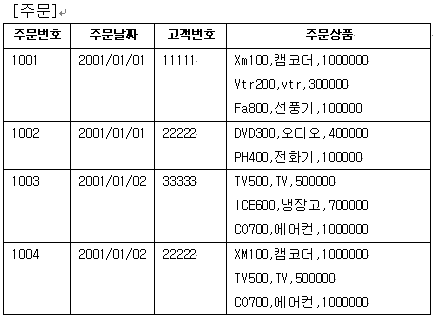
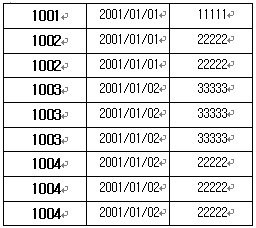
1차 정규화를 시작하자. 이 테이블에서의 문제는 다음과 같다. 된다. ㄱ. 고객 정보 부분을 다른 테이블로 분할을 할 때 생각을 해야할 것이 있다. 주문 테이블에서 떼어 낸 후 연결을 할 매개체를 지정해야 하는 것이다. 그 연결은 ‘고객번호’필드로써 설정을 했다. 그러므로 주문 테이블에서 고객번호 필드만을 남겨두고 고객 정보 모두를 제거 한다.
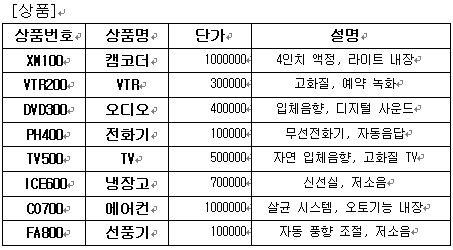
고객 정보는 다음과 같이 테이블을 구성한다. 이렇게 테이블을 분할함으로써 왕관의 데이터가 한번만 존재하게 되었다. 이것이 바로 중복 데이터의 제거이다. 이러므로 공간 절약과 중복 값들 사이의 모순을 방지할 수 있게 된 것이다.
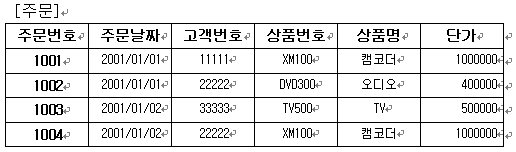
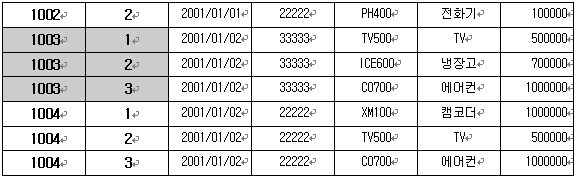
결과 테이블을 보면 상품의 분할이 이루어져 원소성을 유지함을 알 수 있다. 그런데 기본 키 필드인 ‘주문번호’가 기본 키의 유일성이 깨져있다. 결과를 위한 각각의 행들은 고유한 데이터로써 분할은 했으나 기본 키 설정이 부적절하게 되어 데이터 식별이 어렵다. 이를 해결하기 위해서는 기본 키 추가 필드를 하나 더 만들도록 하자(다른 방법이 없는 것은 아니지만 지금으로써는 최선이라고 본다). 바로 복합 키를 설정하겠다는 뜻이다. 고객이 상품 주문 순서에 따른 필드를 하나 추가 하여 주문번호 필드와의 복합으로 기본 키 설정을 해 보면 다음의 테이블과 같이된다.
위 결과와 같이 각 주문에 대한 순서를 정하여 두개의 필드를 기본 키 설정으로 하게 되면 각 행들을 고유하게 식별할 수 있게된다.
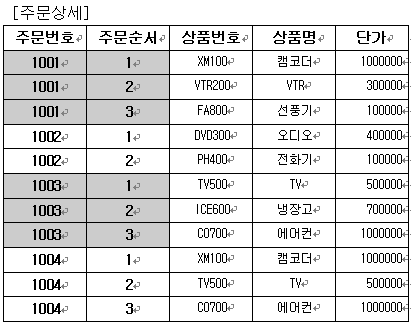
ㄱ. 2NF의 규칙 만족해야 한다. [주문상세] 테이블을 보면 기본 키가 아닌 상품번호에 의존하는 필드들이 있다. 바로 상품명과 단가 필드들인데 이 필드들은 다른 테이블로 분할을 해야 한다.
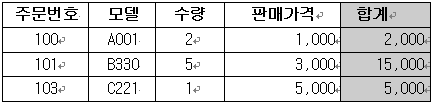
이렇게 해서 3차 정규형식중 ‘키가 아닌 필드에 의존하는 필드가 없어야 한다’를 만족 시켰고 나머지 하나인 필드연산에 의한 결과값을 가지는 필드는 아예 만들질 않았다. 그러면 결과값 필드 라는 것이 무엇일까? 다음의 예제 테이블에서 이것을 알아보자
이 테이블들을 관계 형성을 하는 다이어그램으로 나타내 보자 실습을 위해서 EM에서 ‘shop’ 이라는 데이터베이스를 생성을 한다(3M). 다이어그램을 실행후 다음의 테이블들을 생성하고 관계설정을 한다.
 |




|
상상플러스 - 최근 공지
-
pelly.ryu 2016
라고 적고 보니 4번이 눈에 띄었네요. 지우려고 ... -
pelly.ryu 2016
저처럼 누군가 또 찾아올 것 같아 남깁니다.. `$c... -
와우 2014
깔끔하게 풀어두셔서 많은 도움이 되었습니다 ^^ ... -
ghewffsef 2014
잘배우고 갑니다.. 말한마디 한마디 가슴에 와... -
지나가던길 2014
고맙습니다. 많은 참고가 되었습니다.
0