3. XML Parser - rssParser.js
먼저의 post에서 var xml = rssParser(req.responseXML); 를 보셨을 것입니다.
req.responseXML 을 받아서 JSON으로 파싱 하는 것입니다.
이부분은 rssParser.js란 javascript파일로 따로 구현해 보았습니다.
먼저 전체 소스를 보시죠.
0: /**
1: * @(#)rssParser.js V0.1 2007/03/15
2: *
3: * rss XML Parser extend Prototype.js v1.5
4: * Copyright 2005-2007 by VRICKS, All Right Reserved.
5: * http://www.vricks.com
6: *
7: * GNU LESSER GENERAL PUBLIC LICENSE
8: * TERMS AND CONDITIONS FOR COPYING, DISTRIBUTION AND MODIFICATION
9: *
10: * @Author Woo-Chang Yang, routine@vrick.com
11: */
12:
13: function rssParser(xml) {
14: var v = Try.these(
15: // Rss ¹öÀüÀ» °¡Á® ¿É´Ï´Ù.
16: function() {
17: return xml.getElementsByTagName("rss")[0].getAttribute("version") ? "2.0" : false;
18: },
19: function() {
20: return xml.getElementsByTagName("rdf:RDF")[0].getAttribute("xmlns") ? "1.0" : false;
21: },
22: function() {
23: return xml.getElementsByTagName("feed")[0].getAttribute("xmlns") ? "atom" : false;
24: }
25: )
26: switch(v) {
27: case "2.0" : return new rssParser2(xml); break;
28: case "1.0" : return new rssParser1(xml); break;
29: case "atom" : return new rssParserAtom(xml); break;
30: default : return false;
31: }
32: };
33:
34: // Rss 2.0 Calss
35: var rssParser2 = Class.create();
36: Object.extend(rssParser2.prototype, {
37: initialize : function(xml) {
38: var channel = xml.getElementsByTagName("channel")[0];
39: this.title = channel.getElementsByTagName("title")[0].firstChild.nodeValue;
40: this.link = channel.getElementsByTagName("link")[0].firstChild.nodeValue;
41: if(channel.getElementsByTagName("image")[0]) {
42: var images = channel.getElementsByTagName("image")[0];
43: this.image = {
44: "url" : images.getElementsByTagName("url")[0].firstChild.nodeValue,
45: "title" : images.getElementsByTagName("title")[0].firstChild.nodeValue,
46: "link" : images.getElementsByTagName("link")[0].firstChild.nodeValue
47: };
48: }
49: else {
50: this.image = {
51: "url" : "",
52: "title" : "",
53: "link" : ""
54: }
55: }
56: this.description = Try.these (
57: function() {
58: return channel.getElementsByTagName("description")[0].firstChild.nodeValue;
59: },
60: function() { return "" }
61: );
62: this.language = Try.these (
63: function() {
64: return channel.getElementsByTagName("language")[0].firstChild.nodeValue;
65: },
66: function() {
67: return channel.getElementsByTagName("dc:language")[0].firstChild.nodeValue;
68: },
69: function() { return ""}
70: );
71: this.pubDate = Try.these(
72: function() {
73: return channel.getElementsByTagName("pubDate")[0].firstChild.nodeValue;
74: },
75: function() {
76: return channel.getElementsByTagName("lastBuildDate")[0].firstChild.nodeValue;
77: },
78: function() { return ""; }
79: );
80: var items = new Array();
81: $A(channel.getElementsByTagName("item")).each(function(i){
82: items.push({
83: "category" : Try.these(
84: function() {
85: return i.getElementsByTagName("category")[0].firstChild.nodeValue;
86: },
87: function() { return "" }
88: ),
89: "title" : i.getElementsByTagName("title")[0].firstChild.nodeValue,
90: "link" : i.getElementsByTagName("link")[0].firstChild.nodeValue,
91: "description" : Try.these (
92: function() {
93: return i.getElementsByTagName("description")[0].firstChild.nodeValue;
94: },
95: function() { return "" }
96: ),
97: "pubDate" : Try.these (
98: function() {
99: return i.getElementsByTagName("pubDate")[0].firstChild.nodeValue;
100: },
101: function() {
102: return i.getElementsByTagName("dc:date")[0].firstChild.nodeValue;
103: },
104: function() { return "" }
105: )
106: })
107: })
108: this.item = items;
109: }
110: });
111:
112: var rssParser1 = Class.create();
113: Object.extend(rssParser1.prototype, {
114: initialize : function(xml) {
115: var channel = xml.getElementsByTagName("channel")[0];
116: var images = xml.getElementsByTagName("image")[0];
117: this.title = channel.getElementsByTagName("title")[0].firstChild.nodeValue;
118: this.link = channel.getElementsByTagName("link")[0].firstChild.nodeValue;
119: this.image = {
120: "url" : images.getElementsByTagName("url")[0].firstChild.nodeValue,
121: "title" : images.getElementsByTagName("title")[0].firstChild.nodeValue,
122: "link" : images.getElementsByTagName("link")[0].firstChild.nodeValue
123: };
124: this.description = channel.getElementsByTagName("description")[0].firstChild.nodeValue;
125: this.language = channel.getElementsByTagName("dc:language")[0].firstChild.nodeValue;
126: this.pubDate = channel.getElementsByTagName("dc:date")[0].firstChild.nodeValue;
127: var items = xml.getElementsByTagName("item");
128: var itemValue = new Array();
129: for(var i = 0; i < items.length; i++) {
130: itemValue.push({
131: "category" : items[i].getElementsByTagName("category")[0].firstChild.nodeValue,
132: "title" : items[i].getElementsByTagName("title")[0].firstChild.nodeValue,
133: "link" : items[i].getElementsByTagName("link")[0].firstChild.nodeValue,
134: "description":
135: items[i].getElementsByTagName("description")[0].firstChild.nodeValue,
136: "pubDate" : items[i].getElementsByTagName("dc:date")[0].firstChild.nodeValue
137: });
138: };
139: this.item = itemValue;
140: }
141: });
142:
143: var rssParserAtom = Class.create();
144: Object.extend(rssParserAtom.prototype, {
145: initialize : function(xml) {
146: this.title = xml.getElementsByTagName("title")[0].firstChild.nodeValue;
147: this.link = xml.getElementsByTagName("link")[0].getAttribute("href");
148: this.image = {
149: "url" : "",
150: "title" : "",
151: "link" : ""
152: };
153: this.description = xml.getElementsByTagName("info")[0].firstChild.nodeValue;
154: this.language = "";
155: this.pubDate = xml.getElementsByTagName("modified")[0].firstChild.nodeValue;
156: var items = xml.getElementsByTagName("entry");
157: var itemValue = new Array();
158: for(var i = 0; i < items.length; i++) {
159: itemValue.push({
160: "category" : "",
161: "title" : items[i].getElementsByTagName("title")[0].firstChild.nodeValue,
162: "link" : items[i].getElementsByTagName("link")[0].getAttribute("href"),
163: "description":items[i].getElementsByTagName("summary")[0].firstChild.nodeValue,
164: "pubDate" : items[i].getElementsByTagName("created")[0].firstChild.nodeValue
165: });
166: };
167: this.item = itemValue;
168: }
169: });
function rssParser(xml) {...}을 보시면 Rss의 버전을 구해서 알맞은 Class를 호출 하는 부분 입니다.
Try.these (...) 부분이 보이실 것입니다. API 보기
아래에 나열된 function()을 수행하여 먼저 성공한 하나만을 호출 합니다. 정말 멋진 생각입니다. ^^;
var rssParser2 = Class.create();
Object.extend(rssParser2.prototype, { ... }
새로운 Class를 생성하여 prototype을 확장 하였습니다.
Class.create()로 확장을 하면 항상 initialize 를 수행 합니다.
new rssParser2(xml); 하게 되면 자동으로 initialize 부분이 수행이 된다는 의미 입니다.
var channel = xml.getElementsByTagName("channel")[0];
태그명 channel의 첫번째 element를 가져 옵니다. channel이 한개뿐인데 배열로 가져 왔습니다.
태그명으로 가져 올 때는 getElementsByTagName 여기서도 보실수 있듯이 복수형입니다.
그래서 항상 배열형태로 리턴이 됩니다. [0] 이분이 빠지면 에러가 납니다. ^^;
이제 channel의 자식 노드들을 뽑아올 차례 입니다.
this.title = channel.getElementsByTagName("title")[0].firstChild.nodeValue;
<channel>아래에 있는 태그명 <title>의 첫번째 노드의 value를 가져 옵니다.
DOM에 대한 자세한 내용은
URL : http://www.ibm.com/developerworks/kr/library/wa-ajaxintro5/ 을 참고 하시기 바랍니다.
이렇게 title, lilnk, descriiption을 가져옵니다.
pubDate의 경우는 먼저 pubDate 태그를 찾은 후 없으면 lastBuildDate를 그것도 없으면 공백문자를 리턴해 줍니다.
뭐 어려운거 없습니다. 그냥 DOM으로 노드 뽑아 오듯이 하나씩 뽑아서 대입해 주면 됩니다.
<item>태그에 들어있는 각각의 post를 가져올 차례입니다.
$A(channel.getElementsByTagName("item")).each(function(i){ ... })
$A는 Array의 확장판으로 Ruby틱한 배열형태를 사용할 수 있도록 해 줍니다. API 보기
<item>을 돌면서 <item>에 포함한 <title>, <link>, <description>, <pubDate>를 가져와서 JSON형태로 파싱하고
파싱된 것들을 item이란 변수에 배열로 담아 놓습니다.
이렇게 해 놓으면 후에 item[i].title, item[i].link, item[i].description 으로 가져올 수 있습니다.
어떻게 글로 설명을 할려니 더 어려워 진거 같네요.
구현된 모습을 한번 보겠습니다.
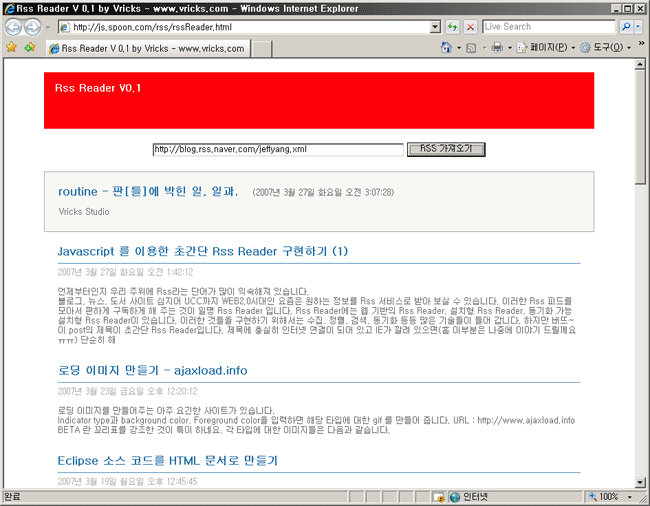
이것으로 이번 post는 마치겠습니다.
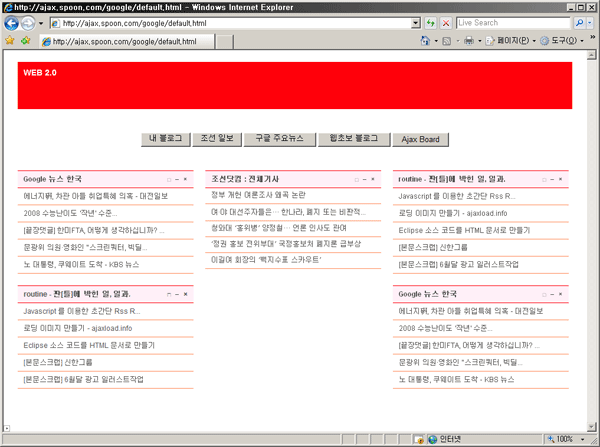
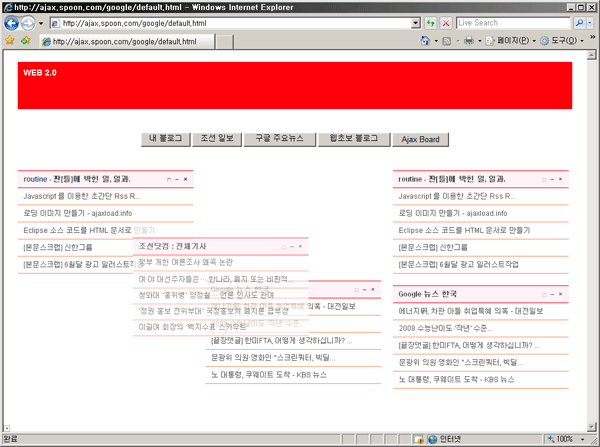
시간이 되면 rssParser.js를 이용한 구글 개인화 페이지를 구현해 보도록 하겠습니다.
물론 prototype.js를 이용할 것이며 Scriptaculous 의 이펙트도 이용할 것입니다.
화면상으로 잠시 맛배기를 ^^;


0