 카페 > 디자인같은 프로그램 강좌 / 디플타임님 카페 > 디자인같은 프로그램 강좌 / 디플타임님 http://cafe.naver.com/dptime/24 http://cafe.naver.com/dptime/24 | |
정규화(NORMALIZATION) 테이블은 행(row)들과 열(column)들로 구성된 하나의 실체이며 데이터의 컬렉션인 엔티티(entity)이다. 하나의 테이블은 다른 테이블들과의 관계(relationship)를 맺을 수 있다. 이 관계 구성의 논리화가 바로 정규화로써 이루어지게 된다. 설계의 출발은 데이터 저장 매체인 엔티티(테이블)들을 구성하는 것이다. 일단은 서비스 흐름에서 찾아지는 기본적인 엔티티를 찾아서 그 엔티티로부터 정규화를 거치는 예를 들어 보도록 한다. 전자제품 대리점에서 고객이 물건을 주문하면 그 고객의 주문 정보가 생성이 된다. 바로 첫번째 엔티티가 생성이 되는 것이다. 그러면 ‘주문’이라는 엔티티에는 어떠한 항목들(필드 설정)이 들어가야하는지 다음의 테이블로 구현을 했다.
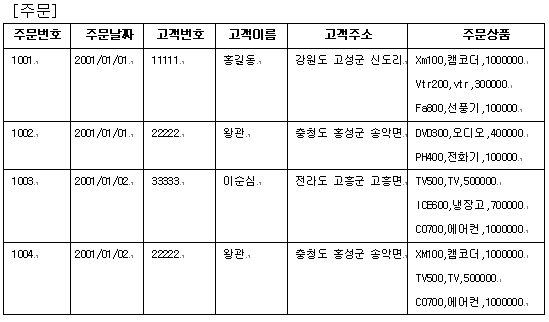
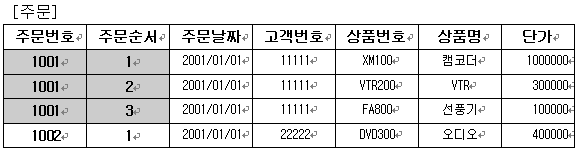
1차 정규형식(1NF, first normal form) 중복된 데이터를 찾아보기 위해 ‘주문’테이블에 다음처럼 발생 가능한 데이터를 입력해 보자. 이 테이블에는 하나의 주문에 대한 모든 정보가 다 들어 있다. 고로, 중복된 데이터가 있을수 있는 것이 된다.
이 테이블은 주문에 대한 자세한 정보가 들어가 있다고 했다. 그러면 왜 이테이블을 분할해야 하는가? 그 이유는 다음과 같다. ㄱ. 데이터를 여러 번 저장하는 것은 공간 낭비 ㄴ. 반복적인 데이터가 존재한다는 것은 데이터의 이동량이 더 크게 된다. 따라서 데이터 버스나 네트워크 대역폭에 더 많은 부담이 생긴다. 이는 전반적인 성능에 상당한 악영향을 미친다. ㄷ. 반복 데이터들 간의 서로 모순된 데이터를 저장할 수 있다. 이것은 데이터 무결성이 깨져버린 것이다.
분리시키는 과정을 거쳐야 하기에 속도가 떨어지게 된다.
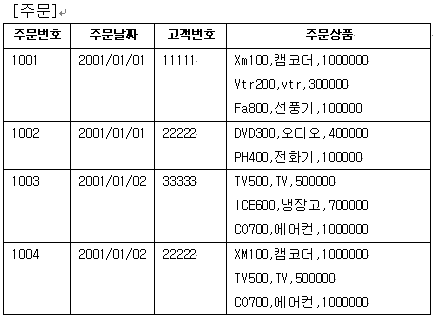
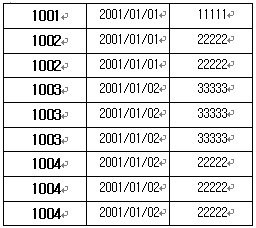
1차 정규화를 시작하자. 이 테이블에서의 문제는 다음과 같다. 된다. ㄱ. 고객 정보 부분을 다른 테이블로 분할을 할 때 생각을 해야할 것이 있다. 주문 테이블에서 떼어 낸 후 연결을 할 매개체를 지정해야 하는 것이다. 그 연결은 ‘고객번호’필드로써 설정을 했다. 그러므로 주문 테이블에서 고객번호 필드만을 남겨두고 고객 정보 모두를 제거 한다.
고객 정보는 다음과 같이 테이블을 구성한다. 이렇게 테이블을 분할함으로써 왕관의 데이터가 한번만 존재하게 되었다. 이것이 바로 중복 데이터의 제거이다. 이러므로 공간 절약과 중복 값들 사이의 모순을 방지할 수 있게 된 것이다.
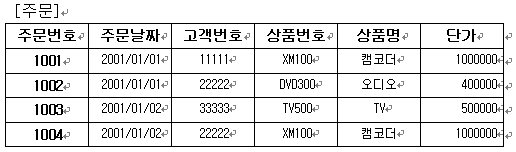
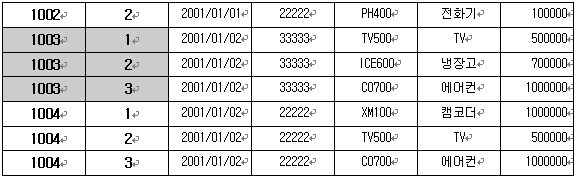
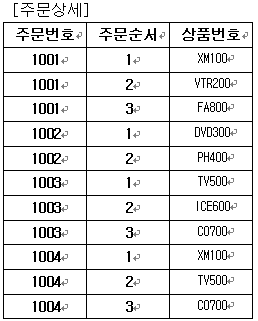
결과 테이블을 보면 상품의 분할이 이루어져 원소성을 유지함을 알 수 있다. 그런데 기본 키 필드인 ‘주문번호’가 기본 키의 유일성이 깨져있다. 결과를 위한 각각의 행들은 고유한 데이터로써 분할은 했으나 기본 키 설정이 부적절하게 되어 데이터 식별이 어렵다. 이를 해결하기 위해서는 기본 키 추가 필드를 하나 더 만들도록 하자(다른 방법이 없는 것은 아니지만 지금으로써는 최선이라고 본다). 바로 복합 키를 설정하겠다는 뜻이다. 고객이 상품 주문 순서에 따른 필드를 하나 추가 하여 주문번호 필드와의 복합으로 기본 키 설정을 해 보면 다음의 테이블과 같이된다.
위 결과와 같이 각 주문에 대한 순서를 정하여 두개의 필드를 기본 키 설정으로 하게 되면 각 행들을 고유하게 식별할 수 있게된다.
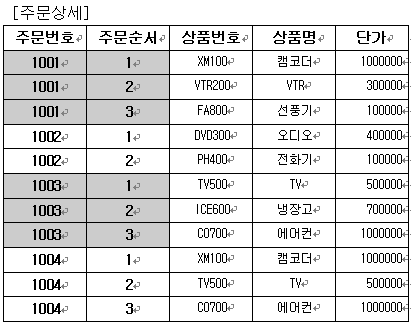
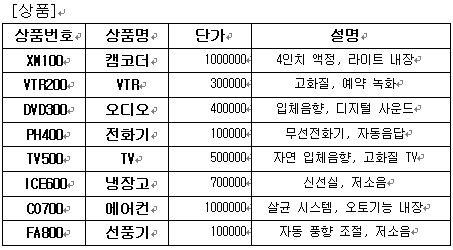
ㄱ. 2NF의 규칙 만족해야 한다. [주문상세] 테이블을 보면 기본 키가 아닌 상품번호에 의존하는 필드들이 있다. 바로 상품명과 단가 필드들인데 이 필드들은 다른 테이블로 분할을 해야 한다.
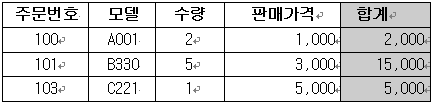
이렇게 해서 3차 정규형식중 ‘키가 아닌 필드에 의존하는 필드가 없어야 한다’를 만족 시켰고 나머지 하나인 필드연산에 의한 결과값을 가지는 필드는 아예 만들질 않았다. 그러면 결과값 필드 라는 것이 무엇일까? 다음의 예제 테이블에서 이것을 알아보자
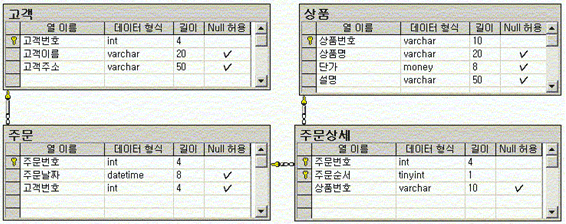
이 테이블들을 관계 형성을 하는 다이어그램으로 나타내 보자 실습을 위해서 EM에서 ‘shop’ 이라는 데이터베이스를 생성을 한다(3M). 다이어그램을 실행후 다음의 테이블들을 생성하고 관계설정을 한다.
 |
Web_developing/Mysql 2006/09/08 12:18




이 글에는 트랙백을 보낼 수 없습니다

by웅쓰
웅자의 상상플러스
|
상상플러스 - 최근 공지
-
pelly.ryu 2016
라고 적고 보니 4번이 눈에 띄었네요. 지우려고 ... -
pelly.ryu 2016
저처럼 누군가 또 찾아올 것 같아 남깁니다.. `$c... -
와우 2014
깔끔하게 풀어두셔서 많은 도움이 되었습니다 ^^ ... -
ghewffsef 2014
잘배우고 갑니다.. 말한마디 한마디 가슴에 와... -
지나가던길 2014
고맙습니다. 많은 참고가 되었습니다.
Copyright ⓒ 2010. 웅쓰, Skin designed by Creasmworks. All rights reserved.
0